What Role Does Automate Data Cleaning and Transformation After Web Scraping Play in Data Engineering?
May 06

Introduction
In modern data engineering, the journey from raw web data to actionable insights depends heavily on how effectively information is processed after extraction. This is where Automate Data Cleaning and Transformation After Web Scraping becomes essential, enabling organizations to convert inconsistent datasets into reliable business intelligence.
With the growing reliance on a Web Scraping API, businesses can collect data at scale from multiple sources such as e-commerce platforms, travel sites, and social media channels. However, scraped data often includes duplicates, missing values, formatting inconsistencies, and irrelevant noise. Without proper cleaning and transformation, such data can lead to inaccurate insights and flawed decision-making.
Automated workflows in data pipelines help streamline these processes by standardizing formats, enriching datasets, and ensuring compatibility with analytics tools. As organizations scale their data initiatives, integrating automated cleaning and transformation processes becomes a fundamental requirement for building resilient, high-performance data ecosystems that support real-time analytics and strategic growth.
Managing Data Inconsistencies Across High-Volume Data Streams Efficiently
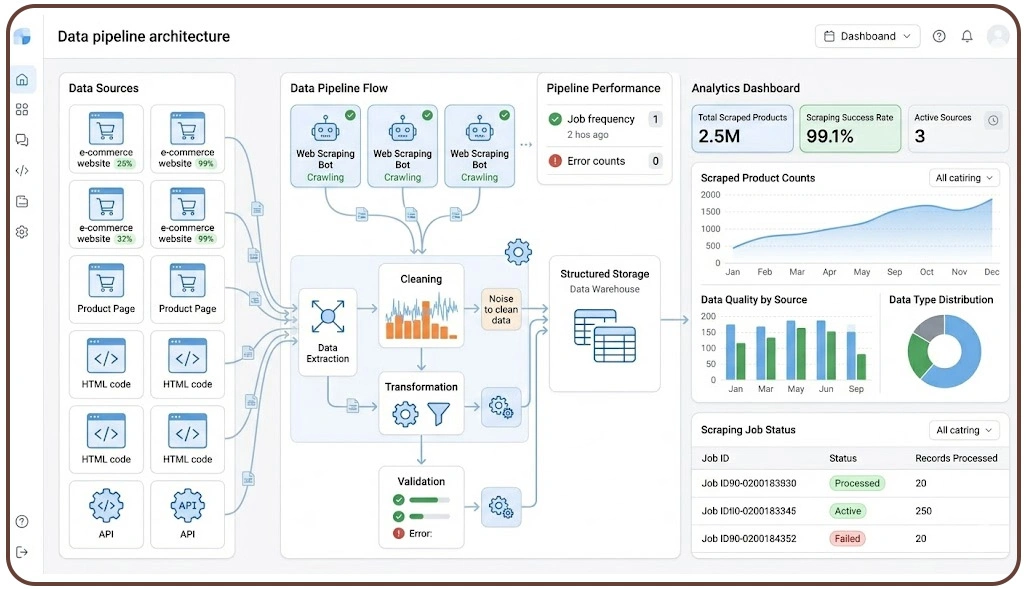
Handling inconsistencies in large-scale datasets remains a core challenge in modern data workflows. When data is collected continuously from multiple digital sources, variations in structure, format, and completeness can disrupt downstream analytics. This becomes more evident in Scalable Pipelines for Mobile App Data Scraping, where frequent updates and platform differences introduce irregularities.
To address this, organizations design structured workflows supported by Data Pipeline Architecture for Web Scraping Projects, ensuring that incoming data is validated and standardized before storage. Automated validation rules help detect anomalies early, while transformation layers align formats for consistency.
Common Issues and Resolution Methods:
| Issue | Impact | Resolution Approach |
|---|---|---|
| Duplicate Entries | Misleading reporting | Automated deduplication |
| Missing Attributes | Partial datasets | Smart data imputation |
| Format Variations | Integration challenges | Schema standardization |
| Noisy or Irrelevant Data | Reduced data usability | Filtering mechanisms |
Practical Improvements:
- Continuous validation reduces data inconsistencies
- Automated checks ensure uniform data formats
- Early-stage filtering improves downstream processing
- Structured workflows minimize manual corrections
- Standardization enhances cross-platform compatibility
- Monitoring systems detect anomalies in real time
Industry findings indicate that automated validation processes can reduce inconsistencies by over 60%, significantly improving data reliability. By embedding these practices into pipeline design, businesses ensure that data remains accurate and analytics-ready.
Structuring Data Transformation Workflows for Faster Analytical Outcomes
Transforming raw datasets into meaningful formats is essential for enabling effective analytics. Organizations relying on Web Scraping Services often encounter diverse data structures, requiring a unified transformation strategy to align datasets for business use. Without proper transformation, even clean data cannot deliver actionable insights.
Implementing the Best ETL Pipeline for Web Scraping Data Processing allows seamless conversion of extracted data into structured formats suitable for storage and reporting. These pipelines perform tasks such as normalization, aggregation, and enrichment, ensuring compatibility with analytics platforms.
Additionally, Cloud-Based Data Transformation Pipelines for Scraping Data provide flexibility and scalability, allowing businesses to process large volumes of data efficiently without infrastructure constraints.
Core Transformation Techniques:
| Technique | Purpose | Outcome |
|---|---|---|
| Normalization | Standardize data formats | Improved consistency |
| Aggregation | Combine multiple data points | Simplified analysis |
| Enrichment | Add external context | Deeper insights |
| Schema Alignment | Match structural formats | Better integration |
Workflow Enhancements:
- Automated pipelines reduce processing delays
- Standard schemas improve interoperability
- Cloud systems support dynamic scaling
- Real-time transformation enables quick reporting
- Reduced manual work lowers operational costs
- Integrated workflows improve data accessibility
Reports suggest that structured transformation workflows can improve analytics efficiency by up to 50%. By adopting advanced pipeline strategies, organizations can ensure that their data is not only clean but also optimized for faster, more accurate decision-making.
Building Reliable Data Systems for Scalable Business Intelligence Outcomes
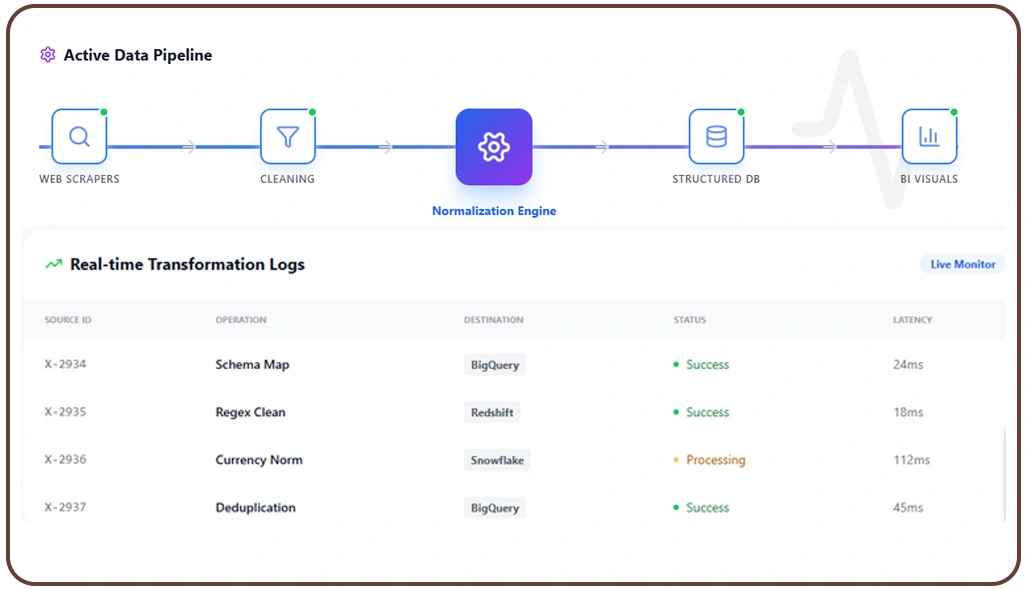
Generating meaningful insights from large datasets requires more than just data collection—it depends on how effectively the data is prepared for analysis. Businesses conducting Market Research rely on accurate and structured datasets to identify trends, understand customer behavior, and evaluate competition.
Applying Data Cleaning and Normalization Techniques via Crawler ensures that datasets remain consistent and analysis-ready. These techniques eliminate redundancies, standardize formats, and improve data quality, enabling better performance in analytical models.
Furthermore, implementing Scalable Data Pipelines for Large-Scale Web Scraping allows organizations to process and analyze growing data volumes without compromising speed or accuracy. These pipelines support continuous data flow and enable real-time insights.
Impact on Data-Driven Operations:
| Factor | Before Optimization | After Optimization |
|---|---|---|
| Processing Speed | Delayed | Near real-time |
| Data Consistency | Variable | Standardized |
| Insight Accuracy | Moderate | High |
| Operational Efficiency | Limited | Improved |
Strategic Advantages:
- Faster access to actionable insights
- Improved decision-making accuracy
- Enhanced scalability for growing datasets
- Real-time analytics capabilities
- Reduced operational bottlenecks
- Stronger competitive positioning
Studies show that organizations using scalable processing systems experience up to 45% improvement in decision-making speed. This structured approach ensures long-term sustainability and supports continuous innovation in data-driven environments.
How Web Data Crawler Can Help You?
Modern businesses require reliable solutions to manage complex data workflows efficiently. By implementing Automate Data Cleaning and Transformation After Web Scraping, we enable organizations to convert raw scraped data into structured, analytics-ready datasets with minimal manual effort.
Our platform is designed to handle end-to-end data processing challenges, ensuring accuracy, scalability, and speed across all operations.
Key Capabilities:
- Advanced data validation for improved accuracy
- Intelligent deduplication to remove redundant entries
- Seamless integration with analytics tools
- Real-time data processing for faster insights
- Custom workflows tailored to business needs
- Secure and compliant data handling
In addition to these capabilities, we implement Cloud-Based Data Transformation Pipelines for Scraping Data to support high-volume processing and ensure flexibility across cloud environments.
Conclusion
Efficient data processing is the backbone of successful analytics, and integrating Automate Data Cleaning and Transformation After Web Scraping ensures that organizations can consistently produce high-quality, reliable datasets. As data volumes continue to grow, automation becomes essential for maintaining accuracy, reducing manual workload, and improving overall efficiency in data engineering workflows.
By adopting structured systems such as Scalable Data Pipelines for Large-Scale Web Scraping, businesses can handle complex data operations with ease and deliver faster insights to stakeholders. Get started today with Web Data Crawler and transform your data into powerful business intelligence.