How do Scalable Pipelines for Mobile App Data Scraping Solutions Enable 90% Faster Data Processing?
April 30

Introduction
In today's data-driven digital economy, organizations rely heavily on accurate, real-time insights derived from mobile platforms. However, extracting and processing massive volumes of app data is no longer a simple task. Businesses face challenges like latency, unstructured data formats, and inconsistent performance when scaling their data workflows. This is where Scalable Pipelines for Mobile App Data Scraping Solutions become critical to achieving operational efficiency.
Modern enterprises increasingly depend on Web Scraping Services to capture high-frequency app data across multiple sources. Yet, without robust pipelines, even the most advanced scraping systems struggle to maintain performance at scale. From ingestion to transformation and storage, each stage must be optimized for speed, resilience, and accuracy.
A scalable pipeline not only improves throughput but also reduces processing time by up to 90%, enabling faster decision-making. By integrating automation, distributed computing, and intelligent data routing, businesses can transform raw app data into actionable intelligence. This blog explores how scalable architectures solve real-world challenges and drive measurable improvements in mobile data processing.
Eliminating System Delays with Distributed Data Processing Architecture
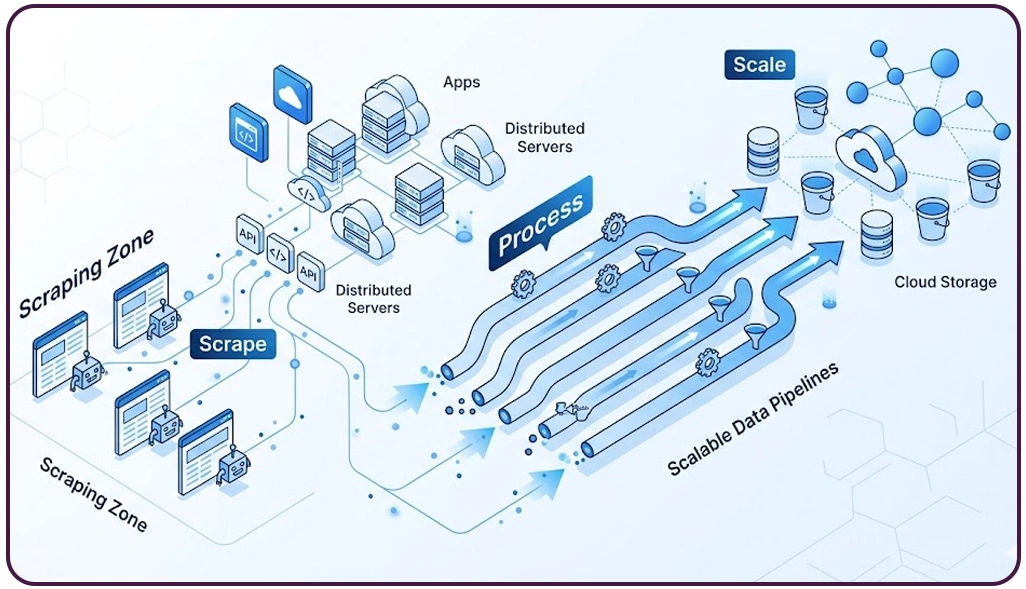
One of the most critical challenges in large-scale data extraction is managing system slowdowns caused by inefficient processing layers. Traditional setups often fail to handle increasing workloads, resulting in delayed outputs and inconsistent data delivery.
In the context of Mobile App Scraping, breaking down large data requests into smaller parallel tasks significantly improves throughput. This approach minimizes processing latency and ensures that even high-frequency data streams are handled efficiently without overloading the system.
A major advancement in this area is the adoption of Cloud-Based Scalable Pipelines for App Data Scraping, which dynamically allocate resources based on demand. Additionally, implementing Etl Pipeline Design for Mobile App Data Scraper allows organizations to structure raw data effectively, making it ready for downstream processing and analytics.
Performance Comparison Overview:
| Metric | Traditional Systems | Modern Distributed Pipelines |
|---|---|---|
| Data Processing Speed | Slow | Significantly Faster |
| Failure Rate | High | Minimal |
| Scalability | Limited | Dynamic |
| Resource Utilization | Inefficient | Optimized |
By integrating these technologies, organizations can eliminate bottlenecks, ensure consistent data flow, and achieve substantial improvements in processing efficiency without compromising system stability.
Improving Data Reliability Through Structured Processing Frameworks
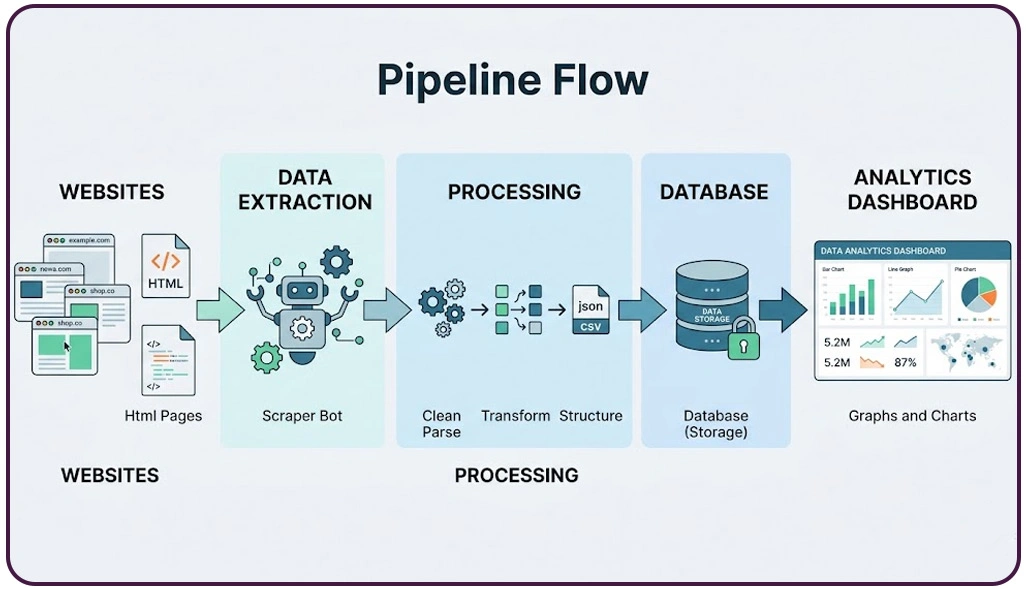
Ensuring data accuracy is essential for businesses relying on insights derived from large datasets. Poorly structured systems often result in duplicate entries, missing values, and inconsistencies that can negatively impact decision-making. To address these issues, organizations are implementing structured processing frameworks that standardize data handling at every stage.
One of the most effective approaches involves using Web Scraping Data Processing Pipelines for Analytics, which enable clean, organized, and validated datasets for deeper analysis. These pipelines ensure that data collected from multiple sources is transformed into a consistent format, reducing the need for manual intervention and improving overall reliability.
For organizations focusing on Competitive Benchmarking, accurate and timely data plays a crucial role in understanding market positioning. Structured pipelines ensure that insights are derived from reliable datasets, enabling businesses to compare performance metrics with confidence.
Data Quality Evaluation Table:
| Parameter | Unstructured Systems | Structured Pipelines |
|---|---|---|
| Data Accuracy | Inconsistent | High |
| Processing Errors | Frequent | Rare |
| Data Duplication | High | Minimal |
| Insight Reliability | Low | Strong |
To further enhance performance, businesses must Optimize Data Pipelines for High-Volume Mobile Data Scraping, ensuring that large-scale data processing remains efficient without sacrificing quality. By implementing structured frameworks, organizations can significantly improve data accuracy, reduce errors, and make informed decisions based on reliable insights.
Enabling Faster Insights with Continuous Real-Time Data Processing Systems
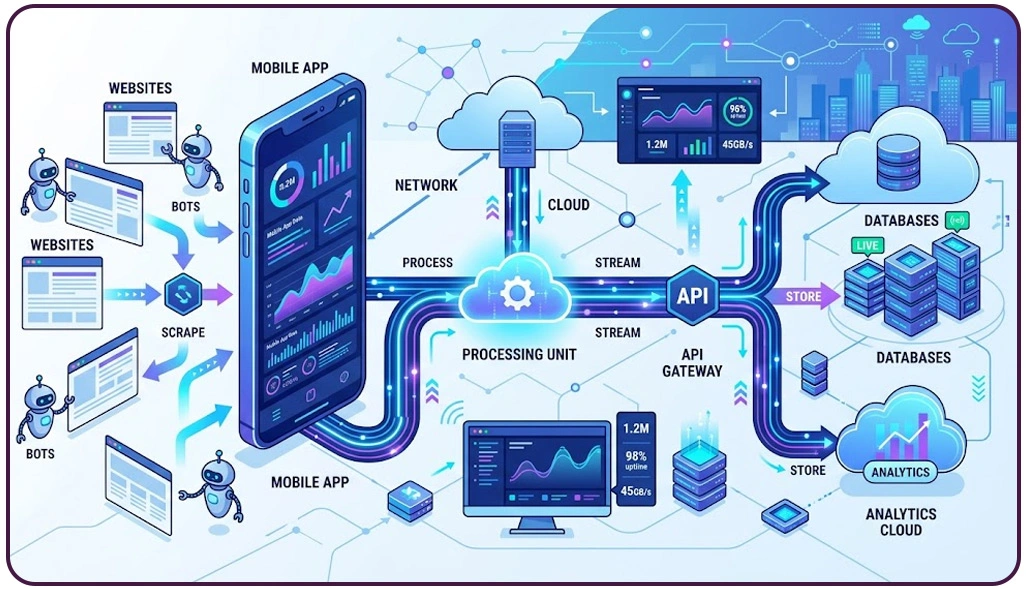
As businesses increasingly rely on immediate insights, the ability to process data in real time has become a necessity rather than a luxury. Traditional batch-processing systems are no longer sufficient for handling continuous data streams, leading to delays in analysis and decision-making. Modern processing systems address this gap by enabling continuous data flow and instant updates.
A key innovation in this space is the use of Real-Time Mobile Data Pipelines Using Web Scraping Tools, which allow organizations to capture and process data as it is generated. This ensures that insights are always current and actionable, providing a competitive advantage in fast-paced industries.
In applications such as Sentiment Analysis, real-time data processing helps businesses monitor customer opinions and feedback instantly. This enables rapid response to changing user preferences and enhances overall customer experience.
Real-Time Processing Comparison:
| Feature | Batch Processing Systems | Continuous Processing Systems |
|---|---|---|
| Data Latency | High | Low |
| Update Frequency | Periodic | Continuous |
| Decision-Making Speed | Delayed | Immediate |
| System Responsiveness | Limited | High |
By adopting continuous processing systems, organizations can reduce latency, improve responsiveness, and ensure that critical insights are always available when needed. This ultimately leads to faster decision-making and improved operational agility.
How Web Data Crawler Can Help You?
Building high-performance data systems requires expertise, infrastructure, and continuous optimization. With deep expertise in Scalable Pipelines for Mobile App Data Scraping Solutions, we deliver tailored strategies to accelerate data processing and improve overall efficiency.
Our Capabilities Include:
- Designing scalable architectures for large-scale data extraction.
- Implementing distributed systems for faster processing.
- Ensuring data accuracy through validation frameworks.
- Integrating automation for seamless workflows.
- Providing real-time monitoring and performance tracking.
- Enhancing system reliability with fault-tolerant designs.
In addition, we specialize in Real-Time Mobile Data Pipelines Using Web Scraping Tools to ensure businesses can access up-to-date insights without delays.
Conclusion
Efficient data processing is no longer optional in today's competitive landscape. Implementing advanced architectures like Scalable Pipelines for Mobile App Data Scraping Solutions ensures faster processing, reduced errors, and better scalability for handling growing data demands.
To maximize performance and maintain efficiency, organizations must adopt strategies such as Optimize Data Pipelines for High-Volume Mobile Data Scraping, ensuring consistent results even under heavy workloads. Connect with Web Data Crawler today and accelerate your journey toward smarter, faster data processing.