What Makes Web Data Extraction From Anti-Bot Protected Websites More Accurate for Large-Scale Crawling?
May 22

Introduction
Modern enterprises depend on large-scale digital intelligence to monitor pricing trends, customer behavior, product availability, and market changes across industries. However, websites today are increasingly protected by advanced anti-bot frameworks designed to identify and restrict automated traffic. These protections create major barriers for businesses that rely on accurate data collection for analytics and operational decisions.
As organizations expand their crawling operations, maintaining consistency, speed, and reliability becomes far more difficult without adaptive scraping strategies. Businesses using Web Data Extraction From Anti-Bot Protected Websites require systems capable of bypassing dynamic detection layers while preserving data accuracy and continuity. Modern anti-bot environments include browser fingerprinting, JavaScript rendering checks, behavioral analysis, and rate limitations that disrupt standard crawling methods.
To address these obstacles, companies are adopting intelligent automation infrastructures combined with rotating proxies, browser emulation, and advanced monitoring systems. Many enterprises also rely on AI Web Scraping Services to improve extraction precision and reduce interruption rates during high-volume crawling sessions. Companies that invest in advanced crawling technologies can maintain uninterrupted data pipelines while supporting strategic decision-making across multiple business environments.
Strengthening Large-Scale Collection Against Detection Systems
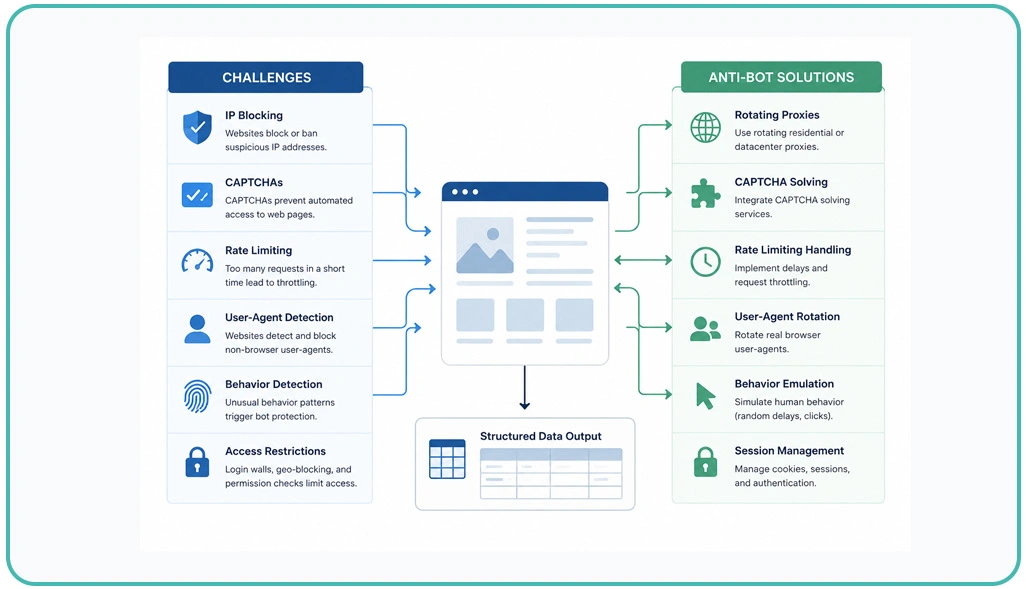
Modern websites actively deploy layered protection mechanisms that monitor user behavior, browser activity, and request frequency to identify automated access attempts. Businesses managing large-scale extraction operations often face interruptions caused by traffic monitoring systems, browser validation checks, and suspicious interaction analysis.
To maintain uninterrupted access, organizations increasingly implement adaptive crawling infrastructures capable of replicating realistic browsing behavior while minimizing detection patterns across protected platforms. Advanced automation systems improve extraction continuity through intelligent session handling, dynamic proxy management, and controlled request scheduling. Businesses addressing Web Scraping Challenges and Anti-Bot Solutions focus heavily on reducing failed requests while improving extraction precision from high-security digital environments.
Modern crawling frameworks additionally use behavioral simulation technologies to mimic scrolling, navigation, and interaction patterns that resemble real users more accurately. Organizations also improve operational consistency through advanced retry systems and browser-rendering workflows supported by a reliable Scraping API environment.
| Detection Barrier | Crawling Impact | Operational Improvement |
|---|---|---|
| Browser Validation | Session interruption | Real browser simulation |
| Traffic Monitoring | Access restrictions | Controlled request pacing |
| Cookie Expiration | Authentication failure | Persistent session handling |
| Request Fingerprinting | Higher block rates | Dynamic browser identities |
| Automated Traffic Analysis | Crawling instability | Human-like interaction behavior |
These infrastructures simplify large-volume extraction while maintaining stability across ecommerce platforms, travel portals, and dynamic business directories. Research indicates that automated traffic monitoring now affects nearly half of enterprise websites, increasing the importance of adaptive extraction systems capable of sustaining continuous data pipelines.
Improving Accuracy Across Dynamically Rendered Platforms
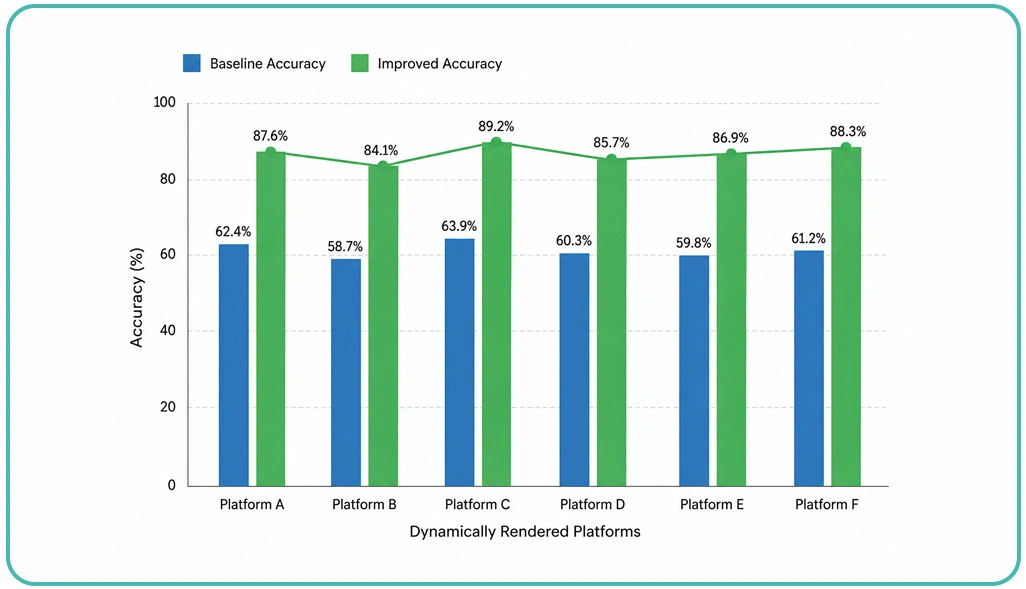
Interactive websites increasingly depend on modern frontend technologies that load content dynamically after user interaction or delayed rendering processes. Traditional extraction tools often struggle to capture structured information accurately because critical data elements remain hidden until scripts finish execution. Businesses requiring reliable digital intelligence therefore invest heavily in advanced rendering environments capable of processing complex web architectures effectively.
Organizations solving Handling JavaScript Heavy Websites in Web Scraping implement headless browser frameworks that interpret asynchronous scripts, delayed API responses, and interactive interfaces before extraction begins. These technologies significantly improve structured data retrieval from ecommerce catalogs, travel listings, and interactive dashboards.
Industry reports suggest that more than sixty percent of enterprise-level websites now rely on JavaScript-based rendering systems, increasing extraction complexity across digital ecosystems. Accurate extraction also supports business analysis initiatives such as Competitive Benchmarking, where organizations compare pricing trends, inventory changes, and customer engagement metrics across multiple competitors.
| Dynamic Website Feature | Extraction Difficulty | Recommended Optimization |
|---|---|---|
| Infinite Scroll Pages | Partial dataset retrieval | Automated scroll rendering |
| Delayed API Responses | Missing information | Async synchronization |
| Interactive Filters | Hidden content elements | Automated interaction flows |
| Dynamic HTML Rendering | Incomplete extraction | Headless browser execution |
| Lazy Loaded Components | Delayed content visibility | DOM wait conditions |
Modern rendering infrastructures combine asynchronous request synchronization, automated interaction simulation, and intelligent parsing systems to improve data completeness. These technologies help organizations maintain reliable extraction performance across continuously evolving digital platforms.
Expanding Scalable Operations Without Access Interruptions
As extraction operations grow across multiple domains and regions, maintaining uninterrupted performance becomes significantly more challenging. Websites continuously monitor connection sources, traffic distribution, and browsing frequency to detect suspicious automation patterns. Businesses managing large-scale crawling projects therefore require infrastructure capable of reducing detection risks while maintaining extraction stability across protected environments.
Organizations implementing Techniques to Avoid IP Blocking While Scraping commonly use residential proxy rotation, geographic traffic distribution, and adaptive throttling systems to reduce repetitive access patterns. These technologies improve accessibility while minimizing the likelihood of connection restrictions during high-volume extraction workflows.
Industry studies show that advanced anti-bot platforms frequently analyze IP reputation scores before granting continued access to digital services. Businesses also address Managing CAPTCHA and Bot Detection in Web Scraping by integrating automated challenge-solving systems, intelligent browser fingerprint rotation, and dynamic session validation workflows. These capabilities improve crawl continuity while reducing operational downtime caused by verification interruptions.
| Scaling Challenge | Operational Risk | Infrastructure Solution |
|---|---|---|
| IP Reputation Monitoring | Restricted accessibility | Residential proxy rotation |
| CAPTCHA Verification | Workflow interruption | Automated solving systems |
| Regional Access Limits | Incomplete visibility | Geo-distributed infrastructure |
| Traffic Pattern Analysis | Increased block frequency | Adaptive request scheduling |
| Massive Concurrent Crawls | Infrastructure instability | Distributed orchestration |
Large organizations performing Enterprise Web Crawling increasingly rely on distributed cloud infrastructures capable of orchestrating thousands of concurrent extraction tasks efficiently. Modern machine learning frameworks further strengthen AI-Powered Anti-Scraping Detection Handling through adaptive behavior analysis and real-time response optimization during extraction sessions.
How Web Data Crawler Can Help You?
Modern organizations require scalable extraction frameworks that can maintain consistent access to complex digital environments without sacrificing accuracy or operational speed. Businesses implementing Web Data Extraction From Anti-Bot Protected Websites can improve decision-making workflows by collecting uninterrupted and structured datasets from highly protected online platforms.
Our approach includes:
- Adaptive browser simulation for intelligent session management
- Distributed proxy infrastructure for uninterrupted access
- Dynamic rendering support for modern web applications
- Automated retry workflows for failed extraction requests
- Real-time monitoring for crawl performance optimization
- Scalable cloud deployment for high-volume operations
Organizations managing advanced extraction environments also benefit from intelligent systems developed for Handling JavaScript Heavy Websites in Web Scraping, enabling accurate collection from interactive and dynamically rendered platforms.
Conclusion
Modern enterprises increasingly depend on accurate digital intelligence to support analytics, pricing optimization, and market monitoring initiatives. Businesses implementing Web Data Extraction From Anti-Bot Protected Websites can improve operational reliability by adopting adaptive crawling infrastructures capable of overcoming evolving detection systems while maintaining scalable performance.
Companies investing in Managing CAPTCHA and Bot Detection in Web Scraping can maintain uninterrupted extraction workflows while improving long-term data accuracy. Contact Web Data Crawler today to build scalable extraction solutions tailored for secure and high-volume crawling operations.