How to Improve Cross Platform Data Delivery Using Scraped Data Integration With JSON, CSV, and Databases?
May 14

Introduction
Modern digital ecosystems depend heavily on structured data flow across multiple platforms, making consistency and automation essential for business intelligence systems. Organizations increasingly rely on Scraped Data Integration With JSON, CSV, and Databases to unify fragmented datasets into usable formats that support analytics, reporting, and decision-making workflows. This approach ensures that raw web data is transformed into structured outputs compatible with internal systems and external APIs.
In today’s competitive environment, companies using Enterprise Web Crawling are able to collect large-scale datasets from dynamic sources, ensuring that no valuable insight is missed during data collection processes. The demand for unified pipelines has led to faster adoption of automation frameworks that streamline extraction, transformation, and loading (ETL) operations.
By converting unstructured web data into standardized formats like JSON, CSV, and database records, enterprises can maintain consistency across multiple platforms while reducing manual intervention. This blog explores how organizations can improve cross-platform data delivery using structured integration techniques, real-time pipelines, and scalable architectures designed for modern data environments.
Strengthening Data Pipelines for Consistent Output Delivery
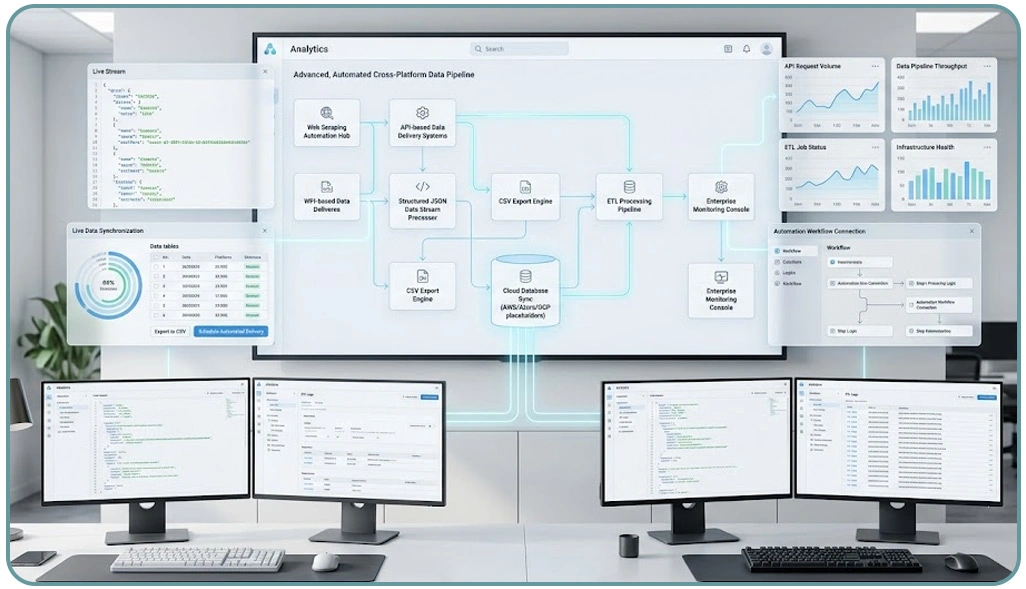
Enterprises are optimizing data pipelines to ensure that information flows smoothly between systems with minimal delay and maximum accuracy. The increasing reliance on structured APIs has made it possible to automate complex workflows that previously required manual intervention. This evolution has significantly improved operational efficiency across industries dealing with large-scale digital data environments.
The adoption of Enterprise Web Scraping With Automated Exports enables organizations to extract, transform, and deliver data in a consistent and repeatable manner. At the same time, Scraping API technologies provide programmable access points that simplify integration with downstream systems, allowing real-time synchronization across platforms.
| Pipeline Component | Function Role | Efficiency Level | Reliability Score |
|---|---|---|---|
| Ingestion Layer | Data intake processing | High | 9/10 |
| Transformation | Format standardization | Very High | 9.5/10 |
| Distribution | System delivery routing | High | 9/10 |
A major focus in modern architectures is ensuring that data remains consistent across different environments such as cloud databases, analytics dashboards, and third-party integrations. This is achieved through validation layers, transformation rules, and monitoring systems that continuously check for anomalies and inconsistencies. These enhancements ensure that data integrity is preserved throughout the entire pipeline lifecycle.
Advancing Data Intelligence for Market Positioning Systems
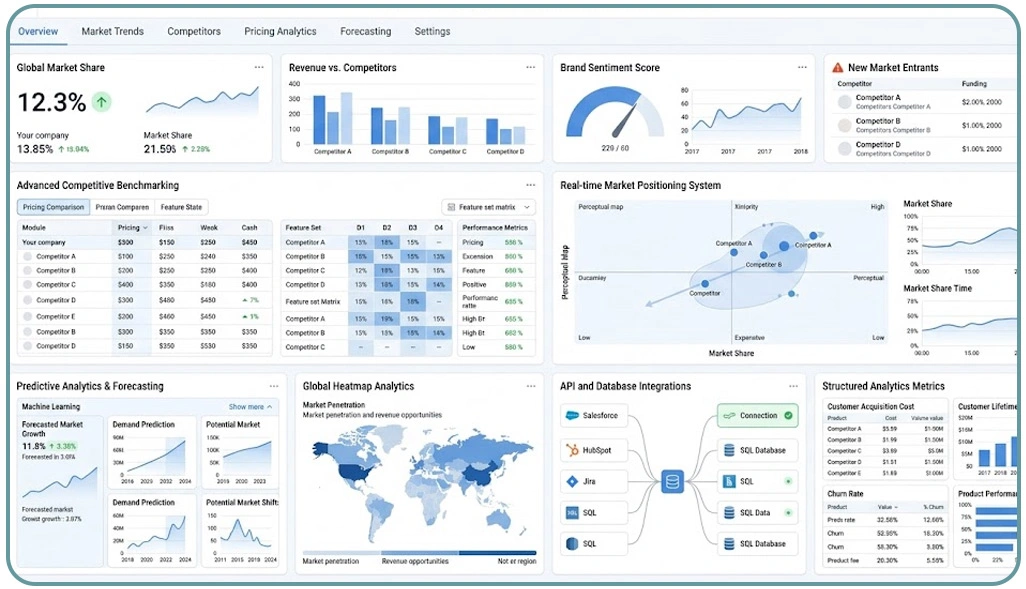
Competitive data intelligence systems have become essential for organizations aiming to maintain strong positioning in rapidly evolving markets. These systems rely on continuous data updates, structured analytics, and automated comparison frameworks that help businesses evaluate performance against industry benchmarks.
The implementation of Competitive Benchmarking allows companies to measure their performance across pricing, product positioning, and market trends using standardized metrics. Additionally, Real-Time Data Delivery to APIs and Databases ensures that insights are updated continuously, enabling faster and more accurate decision-making processes.
| Intelligence Layer | Primary Function | Update Frequency | Strategic Value |
|---|---|---|---|
| Market Tracking | Monitor competitors | Hourly | High |
| Price Analysis | Evaluate pricing shifts | Daily | Very High |
| Trend Forecasting | Predict market behavior | Weekly | High |
Organizations are increasingly focusing on predictive analytics capabilities that help anticipate market shifts before they occur. This includes analyzing historical datasets, identifying behavioral patterns, and applying machine learning models to forecast future outcomes. These insights support strategic planning and risk mitigation across business units.
Optimizing Data Infrastructure for Scalable Integration Systems
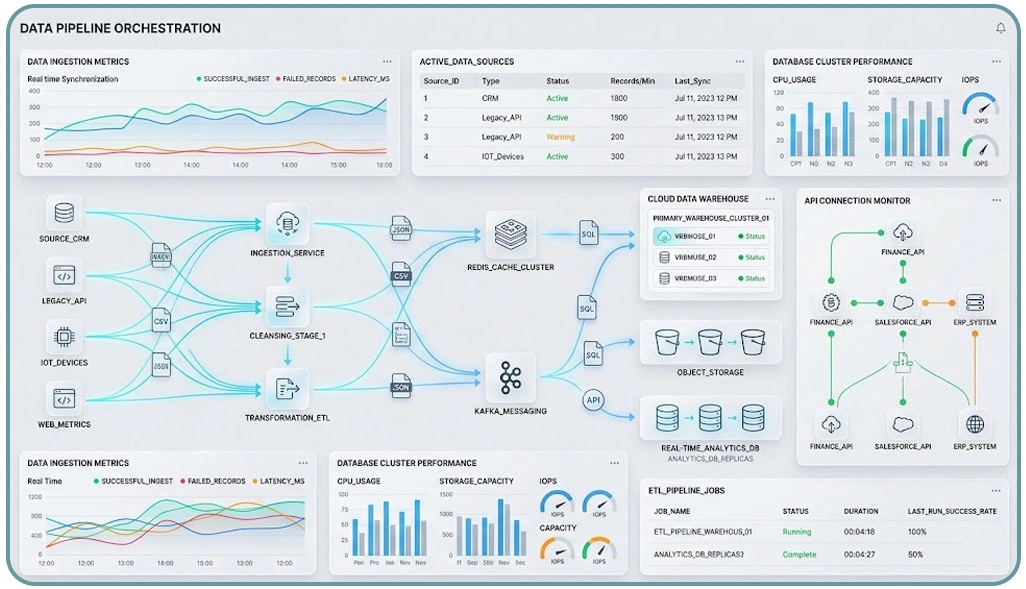
Efficient data infrastructure is critical for ensuring that organizations can scale their operations without performance degradation. Modern systems rely on modular architectures that support flexibility, high availability, and seamless integration across multiple platforms and services.
The evolution of Delivering Scraped Data in Multiple Formats has made it easier for enterprises to distribute structured information across JSON, CSV, and database systems without additional transformation overhead. Similarly, Custom Data Delivery Services for Json, CSV and Database Formats provide tailored output mechanisms that align with specific business requirements and technical environments.
| Infrastructure Layer | Function Role | Scalability Level | Performance Gain |
|---|---|---|---|
| Storage Systems | Data retention | High | 40% |
| Processing Engine | Data transformation | Very High | 55% |
| Delivery Network | Output distribution | High | 50% |
The growing adoption of Mobile App Scraping has expanded the scope of data collection beyond traditional web sources, enabling businesses to capture valuable insights from mobile ecosystems. This has become particularly important for industries focused on user behavior analytics, pricing intelligence, and content tracking.
How Web Data Crawler Can Help You?
Scraped Data Integration With JSON, CSV, and Databases enables businesses to unify diverse datasets into structured formats that support automation and analytics workflows. A robust crawler ensures that data is extracted, transformed, and delivered efficiently across multiple endpoints without manual intervention.
- Extracting large-scale datasets from dynamic sources
- Standardizing output formats for system compatibility
- Ensuring consistent data validation across pipelines
- Supporting multi-source aggregation for analytics
- Reducing manual processing overhead
- Improving data freshness for decision systems
This structured approach aligns with Custom Data Delivery Services for Json, CSV and Database Formats, ensuring that organizations can maintain flexibility while scaling their data infrastructure effectively.
Conclusion
Scraped Data Integration With JSON, CSV, and Databases continues to redefine how organizations manage and operationalize large-scale data ecosystems. By structuring raw inputs into usable formats, businesses can improve efficiency and accelerate decision-making across departments.
The future of digital infrastructure depends on Real-Time Data Delivery to APIs and Databases, enabling seamless synchronization, improved scalability, and stronger analytical accuracy across enterprise systems. Start optimizing your data pipelines today with Web Data Crawler designed for scalable digital transformation.