How to Scrape High-Value Product Attributes With Complex Structure for Faster E-Commerce Insights?
May 21

Introduction
Modern e-commerce ecosystems generate massive volumes of structured and semi-structured product data every second. Brands and marketplaces depend on accurate attribute-level extraction to improve catalog intelligence, competitor benchmarking, and dynamic pricing decisions. In this environment, Scrape High-Value Product Attributes With Complex Structure becomes essential for transforming raw product pages into actionable intelligence.
Businesses rely heavily on Web Scraping Services to extract deeply nested attributes such as variants, bundles, specifications, and multi-layered metadata from complex storefront architectures. However, traditional extraction systems often fail when product structures vary across categories, languages, and marketplaces. This leads to incomplete datasets and inaccurate decision-making. To address this gap, modern pipelines are built to handle hierarchical data models and inconsistent HTML structures.
By focusing on structured extraction techniques, organizations can unify fragmented product data and improve downstream analytics accuracy. One major advantage is improved visibility into competitive catalogs, enabling better positioning and segmentation strategies. This ensures that retail analysts and data teams can interpret market behavior more effectively. Ultimately, structured extraction is no longer optional—it is a foundational requirement for scalable digital commerce intelligence.
Building Unified Product Intelligence Across Multiple Retail Platforms
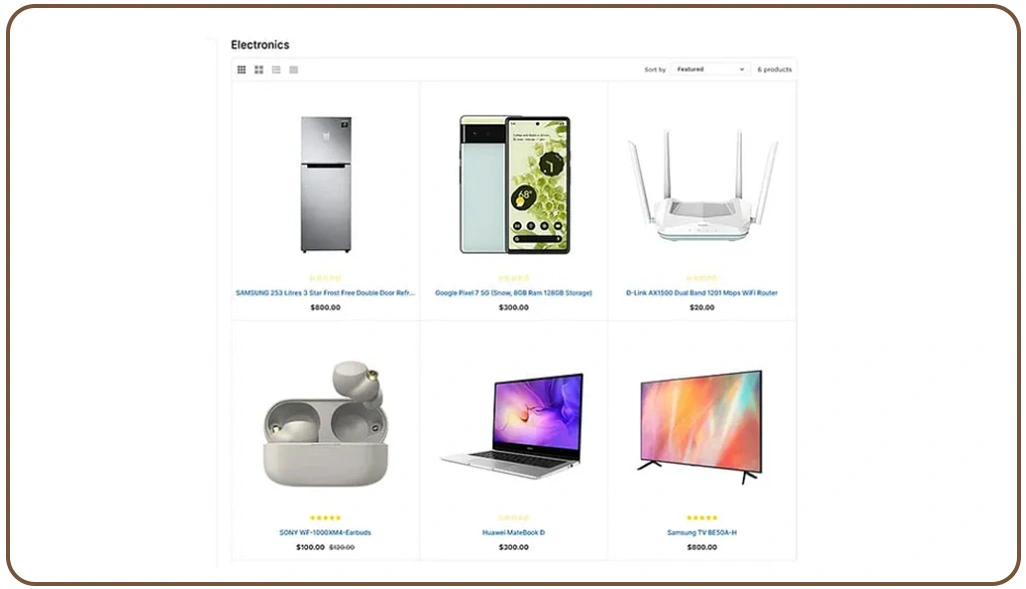
Modern digital marketplaces contain massive amounts of fragmented product information that changes frequently across regions, sellers, and platforms. Businesses often struggle with inconsistent naming conventions, missing specifications, duplicate listings, and pricing variations that reduce the reliability of analytics systems. One of the most important steps in this workflow is Product Data Normalization After Web Scraping, which helps standardize extracted information into unified datasets for consistent comparison and reporting.
Standardization improves attribute accuracy while reducing duplication errors across marketplaces. Retailers and analytics firms also rely on Automated Extraction of Structured Product Data From Marketplaces to capture catalog information from multiple sources in real time. This approach improves operational efficiency and reduces delays in updating product databases.
Accurate extraction systems also contribute significantly to Pricing Intelligence strategies by allowing businesses to compare competitor pricing structures and monitor changes across categories. Faster access to normalized product data enables better margin optimization and promotional planning.
Product Structuring Workflow Overview:
| Data Category | Common Challenge | Structured Output |
|---|---|---|
| Product Titles | Inconsistent naming | Standardized titles |
| Specifications | Mixed formatting | Unified attributes |
| Variant Listings | Duplicate entries | Variant mapping |
| Price Information | Currency differences | Comparable pricing |
Scalable extraction and normalization systems ultimately support stronger forecasting capabilities and more reliable decision-making for e-commerce businesses operating in competitive markets.
Improving Customer Insight Collection From Dynamic Product Sources
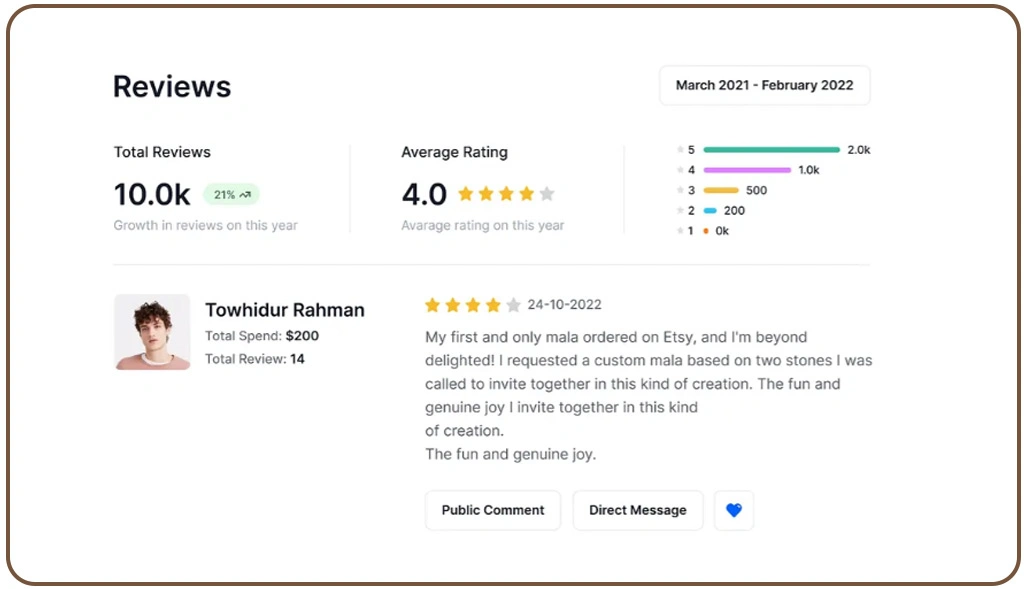
Modern e-commerce websites distribute valuable product insights across multiple page layers, hidden tabs, expandable descriptions, and customer-generated content sections. Organizations increasingly depend on Ai-Based Product Review Data Extraction Services to process customer opinions, sentiment patterns, and product feedback from dynamic online environments.
These advanced extraction systems convert scattered review data into structured insights that support marketing, merchandising, and product improvement initiatives. At the same time, Review Scraping Services help businesses aggregate customer experiences across multiple marketplaces, enabling brands to identify recurring complaints, monitor satisfaction trends, and evaluate competitor performance more accurately.
Many enterprises also implement Complex Website Data Extraction for Ecommerce Businesses to manage highly dynamic product pages that frequently update pricing, availability, specifications, and promotional details. These systems improve extraction consistency while reducing the risk of incomplete datasets.
Customer Insight Extraction Performance:
| Insight Type | Extraction Difficulty | Business Impact |
|---|---|---|
| Customer Reviews | High | Sentiment analysis |
| Product Ratings | Medium | Brand evaluation |
| Feature Mentions | High | Product enhancement |
| Competitive Feedback | Medium | Market positioning |
Advanced extraction workflows provide deeper visibility into consumer behavior and purchasing preferences. By transforming unstructured product content into organized datasets, businesses can strengthen strategic planning, improve product positioning, and respond more effectively to changing customer expectations in competitive retail markets.
Scaling Enterprise Data Collection Across Large Digital Catalogs
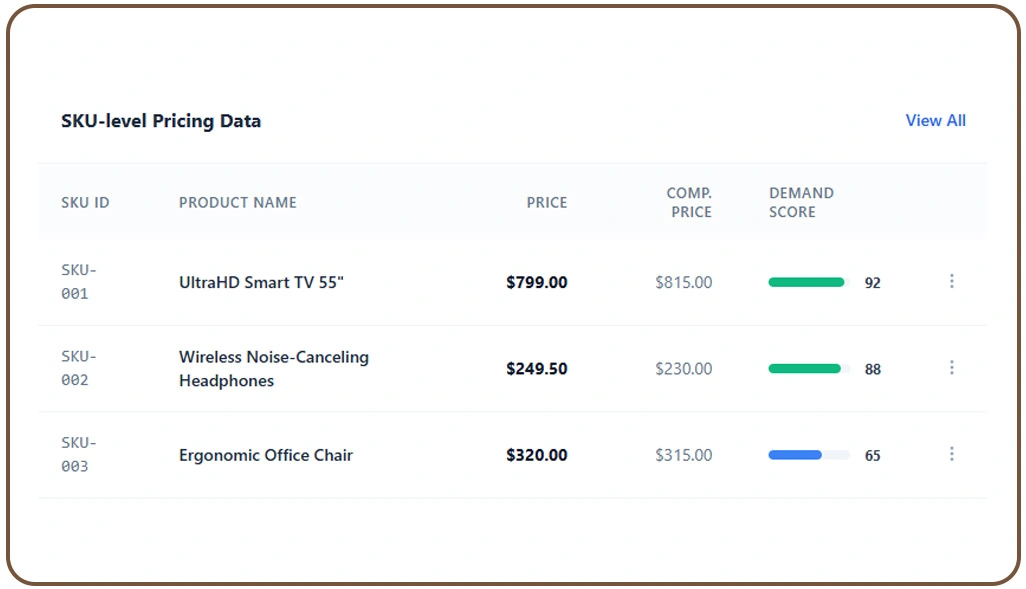
As online retail ecosystems continue expanding, businesses must process increasingly large volumes of product information across multiple platforms and marketplaces. Managing these datasets manually becomes inefficient due to constant catalog updates, pricing fluctuations, and changing inventory structures. Many organizations deploy advanced Web Crawler systems to automate the navigation and collection of structured product information from complex website architectures.
These systems help businesses capture detailed product attributes, pricing information, seller data, and inventory updates without manual intervention. To improve analytical precision, enterprises also use Extract SKU-Level Product Data for Analytics for tracking individual product variations, inventory movement, and category-level performance metrics.
SKU-level visibility enables businesses to identify demand trends and optimize supply chain operations more effectively. Scalable extraction infrastructure also supports faster synchronization between data pipelines and analytics platforms, reducing delays in reporting and improving decision-making accuracy across departments.
Enterprise Extraction Scalability Metrics:
| Operational Metric | Standard Systems | Enterprise Systems |
|---|---|---|
| Daily Product Pages | 15K | 4M+ |
| Attribute Accuracy | 75% | 98% |
| Update Frequency | Daily | Real-time |
| Data Processing Speed | Moderate | High-speed |
By implementing automated collection frameworks, organizations can efficiently manage complex retail datasets while improving forecasting accuracy, competitor monitoring, and catalog optimization across large-scale e-commerce environments.
How Web Data Crawler Can Help You?
Efficient data systems are essential for modern retail intelligence, especially when handling large-scale product catalogs with complex structures. The ability to Scrape High-Value Product Attributes With Complex Structure enables organizations to capture granular product details that directly influence pricing, positioning, and inventory decisions.
A powerful data pipeline ensures consistency in extraction while maintaining accuracy across diverse marketplace environments.
- Collects structured product information across multiple marketplaces
- Ensures consistency in dynamic and frequently changing listings
- Improves accuracy of attribute mapping across categories
- Enhances visibility into competitor product strategies
- Supports scalable ingestion for large SKU databases
- Strengthens decision-making through unified data pipelines
The integration of Complex Website Data Extraction for Ecommerce Businesses further enhances the ability to process complex datasets efficiently, enabling businesses to turn raw product data into actionable intelligence.
Conclusion
Efficient product intelligence systems depend heavily on the ability to Scrape High-Value Product Attributes With Complex Structure to ensure that every relevant data point is captured and standardized for analysis. By adopting advanced data extraction strategies, organizations can build more resilient analytics ecosystems and improve overall decision-making accuracy.
When combined with Extract SKU-Level Product Data for Analytics, businesses can achieve deeper visibility into performance trends, pricing shifts, and catalog optimization opportunities across multiple channels. Contact Web Data Crawlertoday to transform raw product data into powerful retail intelligence systems.