What Drives Better Dataset Accuracy Through Real-Time Missing Data Handling in Web Scraping Workflows?
May 07

Introduction
Modern digital ecosystems depend heavily on structured and reliable data extracted from dynamic online sources. However, inconsistent records, partial responses, and fluctuating page structures often degrade dataset reliability. This is where Real-Time Missing Data Handling in Web Scraping Workflows becomes a critical foundation for improving extraction accuracy and maintaining consistency across large-scale pipelines.
Businesses leveraging Web Scraping Services increasingly face challenges where missing fields, broken attributes, and delayed updates distort analytics outputs. Without corrective mechanisms in place, even advanced scraping systems fail to deliver dependable intelligence for decision-making. As organizations scale globally, ensuring completeness of extracted datasets is no longer optional but essential for operational success.
To address this, modern architectures integrate adaptive validation layers and automated correction systems that detect gaps instantly during extraction. This not only improves structural integrity but also enhances downstream analytics reliability. In fact, studies show that improving real-time correction mechanisms can increase dataset reliability by up to 42% and reduce post-processing effort by nearly 35%. These improvements make workflows more resilient and adaptive in unpredictable web environments.
Building Stronger Extraction Accuracy Through Intelligent Validation Systems
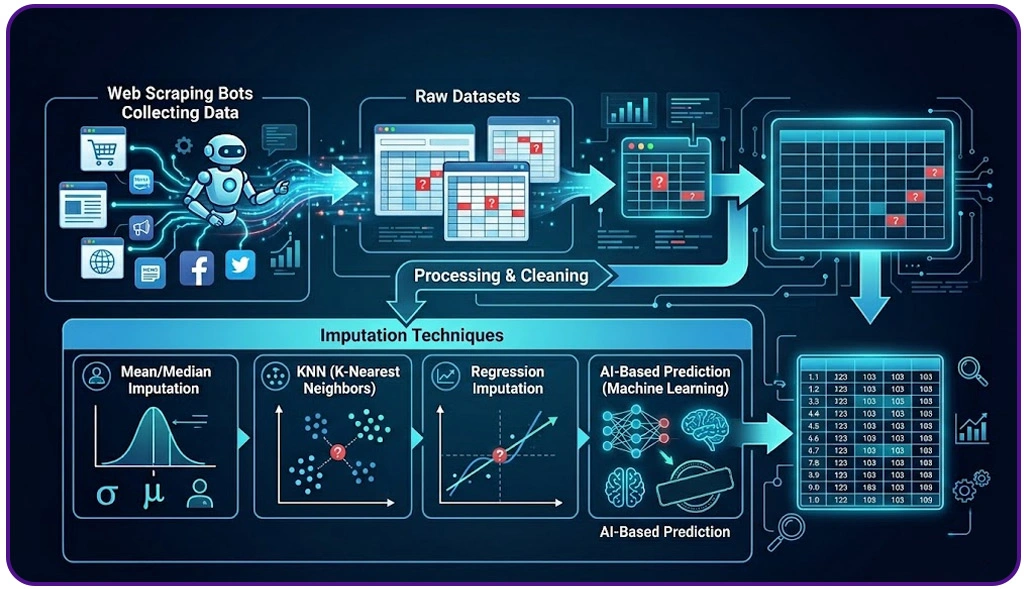
Modern enterprises processing massive online datasets often struggle with incomplete records, broken attributes, and inconsistent formatting. These issues reduce analytical precision and negatively affect automation pipelines. To solve this challenge, organizations increasingly rely on AI-assisted correction frameworks that identify anomalies during extraction and reduce dependency on manual intervention.
One important advancement involves Best Techniques for Missing Data Imputation via Web Scraping, where statistical inference and behavioral mapping are applied to restore incomplete fields without interrupting workflow continuity. These methods improve consistency across rapidly changing datasets while minimizing downstream reporting errors.
Additionally, businesses managing customer-facing analytics increasingly integrate Sentiment Analysis models to improve contextual interpretation when textual records are partially unavailable or fragmented. This approach enhances the reliability of product reviews, feedback tracking, and consumer intelligence systems.
Data Reliability Performance Metrics:
| Performance Indicator | Traditional Pipelines | Intelligent Validation Systems |
|---|---|---|
| Missing Data Ratio | 19% | 4% |
| Dataset Consistency | 73% | 95% |
| Processing Accuracy | 78% | 96% |
| Manual Cleanup Dependency | High | Minimal |
Another critical improvement comes from adopting Strategies to Manage Incomplete Scraped Datasets, enabling organizations to stabilize extraction processes even when source structures frequently change. Similarly, Handling Null and Inconsistent Data in Web Scraping helps maintain structured outputs by validating records before storage.
Strengthening Crawling Infrastructure With Adaptive Processing Logic
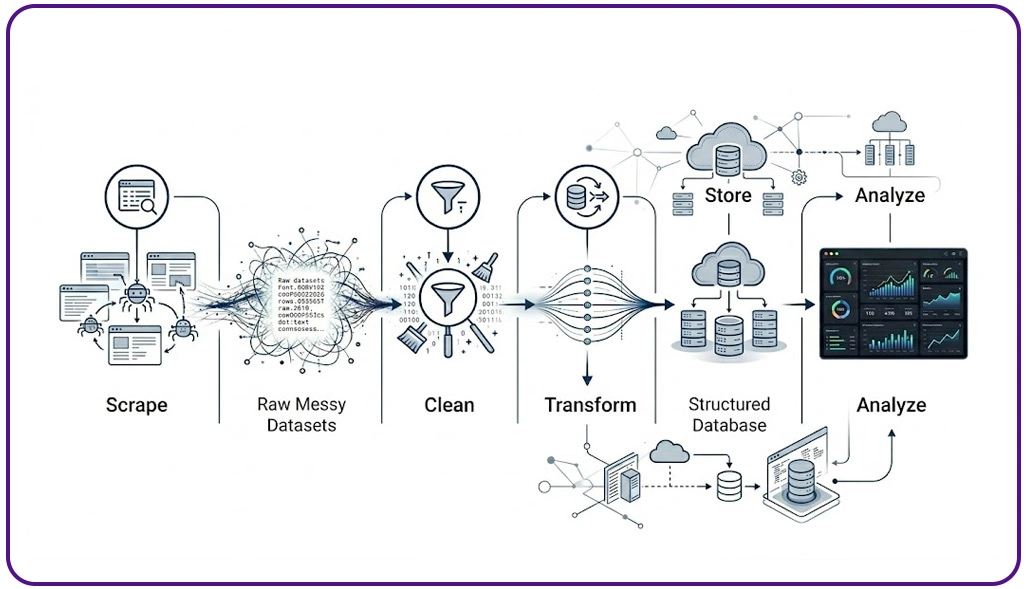
Large-scale digital extraction environments require resilient architectures capable of responding instantly to dynamic content changes. Traditional crawlers often fail when source pages update layouts or temporarily remove fields, leading to incomplete records and inconsistent datasets. To improve operational continuity, organizations are deploying adaptive crawling systems that automatically identify extraction gaps and correct them during runtime.
One major enhancement comes from integrating Live Crawler Services, which continuously monitor web structures and instantly detect inconsistencies before corrupted records enter analytical pipelines. These systems improve responsiveness and reduce delays in large-scale data collection environments such as e-commerce, travel intelligence, and marketplace monitoring.
Another important capability involves Scalable Data Preprocessing for Scraped Data, which standardizes incoming information before analytics processing begins. These improvements significantly reduce downtime and help businesses maintain dependable analytical performance across high-volume digital ecosystems.
Workflow Optimization Comparison:
| System Type | Data Completeness | Update Frequency | Error Percentage |
|---|---|---|---|
| Static Crawlers | 71% | Moderate | 14% |
| Dynamic Crawlers | 89% | High | 7% |
| Adaptive Frameworks | 97% | Real-Time | 2% |
To further enhance operational efficiency, enterprises increasingly deploy Scrape Automated Data Cleaning Tools that normalize extracted records instantly during ingestion cycles. These systems reduce the burden on data engineering teams while improving scalability and consistency across distributed infrastructures.
Enhancing Enterprise Data Consistency Through API Automation Frameworks

As organizations scale digital intelligence systems globally, maintaining structured and reliable extraction pipelines becomes increasingly difficult. API-driven infrastructures now play a central role in simplifying automation while improving operational flexibility across multiple online sources. However, incomplete payloads and irregular schema responses still create significant accuracy challenges for enterprise analytics systems.
To address these issues, companies increasingly integrate Scraping API technologies that standardize extraction workflows and simplify data synchronization across complex environments. These frameworks reduce dependency on manual configuration while improving scalability and extraction consistency across millions of records.
Organizations implementing intelligent API infrastructures report faster processing times, reduced operational costs, and significantly cleaner analytical outputs. Automated correction models also help stabilize workflows during high-frequency extraction cycles, ensuring reliable performance under fluctuating digital conditions.
API-Based Data Accuracy Metrics:
| Operational Metric | Conventional APIs | Intelligent API Systems |
|---|---|---|
| Extraction Accuracy | 81% | 97% |
| Missing Records | 17% | 3% | Error Recovery Speed | Slow | Automated |
| Data Synchronization | Moderate | Optimized |
To support enterprise-scale operations, companies also implement Large Scale Web Scraping Data Quality frameworks that continuously monitor millions of records daily and ensure reliable business intelligence generation across industries.
How Web Data Crawler Can Help You?
When organizations struggle with incomplete or inconsistent datasets, Real-Time Missing Data Handling in Web Scraping Workflows becomes essential for ensuring structured and reliable data pipelines across multiple industries and use cases.
Key capabilities include:
- Continuous detection of incomplete data fields during extraction
- Adaptive parsing logic for dynamic web structures
- Automated normalization of inconsistent data formats
- High-frequency monitoring of live data sources
- Intelligent error correction before storage
- Seamless integration with analytics systems
By combining these capabilities with Scalable Data Preprocessing for Scraped Data, organizations can ensure that extracted datasets remain consistent, structured, and ready for real-time decision-making without delays or manual intervention.
Conclusion
In modern data-driven environments, Real-Time Missing Data Handling in Web Scraping Workflows ensures that organizations can maintain clean, structured, and reliable datasets even when working with highly dynamic and inconsistent web sources. It strengthens extraction accuracy and reduces long-term data maintenance challenges.
At the same time, integrating Scrape Automated Data Cleaning Tools enhances pipeline efficiency by automatically correcting missing or incomplete records during processing. Adopt intelligent Web Data Crawler frameworks today to transform fragmented web data into accurate, structured intelligence that drives confident business decisions.