What Are the Legal Considerations of robots.txt in Data Extraction Behind Modern Scraping Success?
May 22

Introduction
Modern businesses depend on structured online information to improve analytics, competitor benchmarking, pricing intelligence, and operational efficiency. Many organizations focus heavily on technical scraping performance while ignoring governance standards that influence long-term sustainability. This is where Legal Considerations of robots.txt in Data Extraction become essential for balancing automation with ethical responsibility.
A properly interpreted robots.txt file helps organizations avoid unnecessary server strain and minimizes the possibility of violating website access expectations. Businesses adopting AI Web Scraping Services are increasingly integrating governance protocols into their workflows because compliance failures may result in blocked IPs, legal notices, or reputational damage.
Industry experts also emphasize the growing relevance of ethical automation standards as regulators and website owners continue strengthening digital access rules. This shift encourages businesses to adopt structured compliance reviews, risk assessments, and documentation processes before launching large-scale extraction initiatives across competitive industries and digital ecosystems.
Establishing Responsible Digital Access Management Frameworks
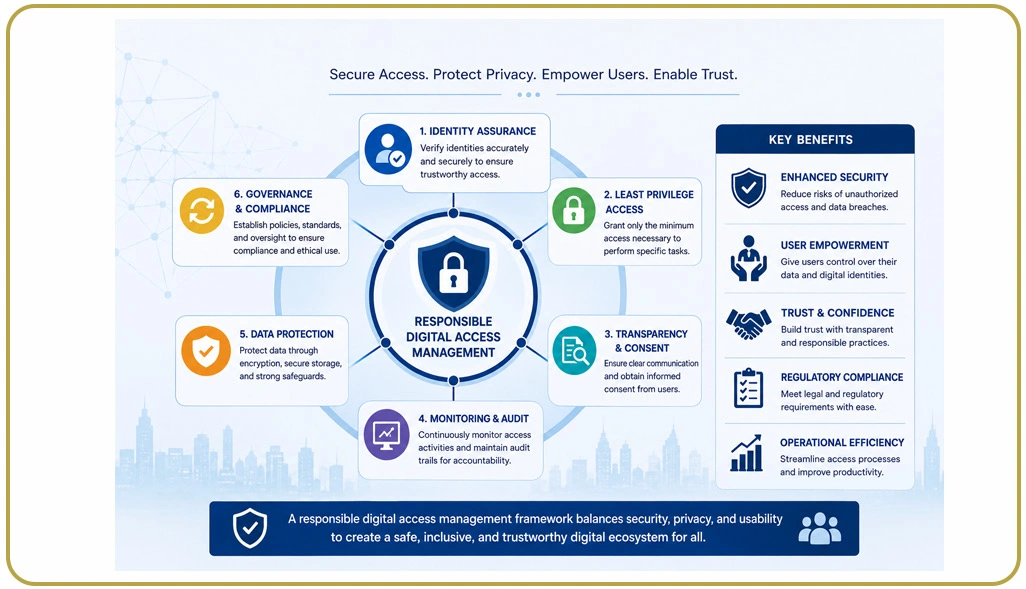
Businesses handling large-scale extraction projects often encounter operational instability when compliance controls are ignored during automated data collection activities. Poorly managed crawling environments may create infrastructure stress, trigger security systems, or generate access restrictions that interrupt business intelligence workflows.
Industry reports indicate that enterprises implementing structured compliance systems experience significantly fewer scraping interruptions compared to organizations operating unmanaged automation frameworks. Many organizations now prioritize Respecting Crawl-Delay Directives During Scraping because unmanaged request frequency can negatively affect website performance and increase blocking risks.
| Governance Component | Operational Purpose | Business Outcome |
|---|---|---|
| Request Monitoring | Controls extraction frequency | Reduces access restrictions |
| Traffic Scheduling | Balances server interaction | Improves platform stability |
| Compliance Tracking | Maintains operational visibility | Supports accountability |
| Risk Assessment | Identifies infrastructure concerns | Minimizes disruptions |
| Audit Documentation | Records extraction activities | Enhances governance |
Businesses integrating Live Crawler Services into enterprise environments often benefit from adaptive scheduling, infrastructure monitoring, and scalable workflow management. These systems help technical teams maintain operational continuity while adjusting extraction behavior according to changing platform conditions and access expectations.
Additionally, companies implementing Web Scraping Compliance Using robots.txt Best Practices generally establish internal governance procedures before launching extraction campaigns. These frameworks support responsible automation practices while improving coordination between technical operations, compliance monitoring, and long-term business intelligence strategies across evolving digital environments.
Improving Automation Reliability Through Structured Access Controls
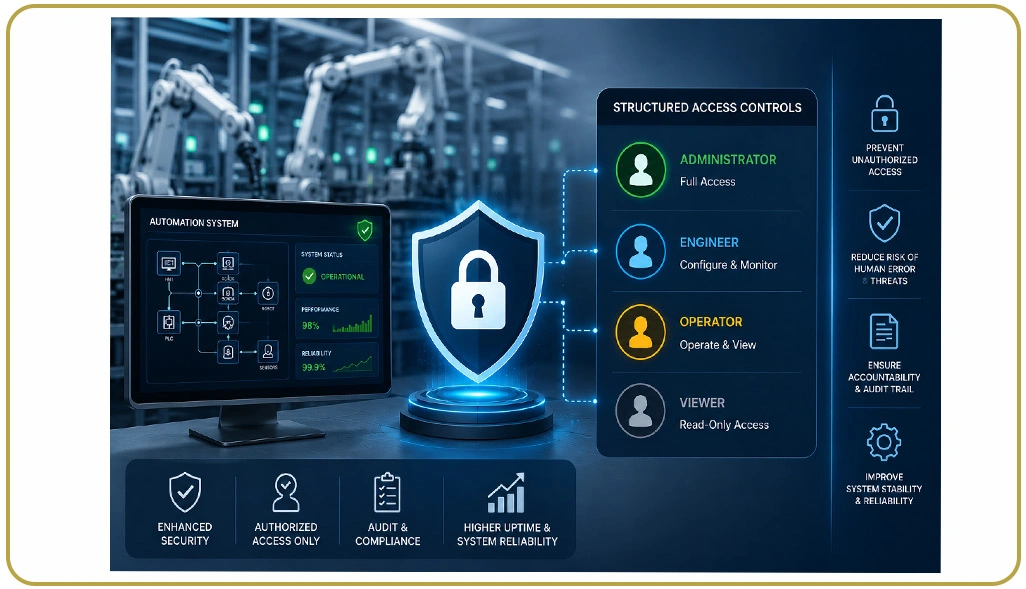
Organizations expanding automated extraction operations frequently face technical challenges related to bandwidth pressure, inconsistent access rules, and infrastructure limitations. Without structured access management strategies, businesses may experience blocked requests, reduced data quality, or unstable collection performance that affects long-term intelligence operations. Responsible automation frameworks help companies maintain extraction reliability while reducing operational risks associated with unmanaged crawling activities.
Research studies show that organizations applying ethical access controls achieve stronger operational continuity and improved extraction accuracy compared to businesses using aggressive collection strategies. A properly configured Web Crawler helps organizations manage scalable extraction workflows while supporting organized navigation and controlled website interaction.
| Technical Area | Recommended Action | Expected Benefit |
|---|---|---|
| Request Distribution | Intelligent traffic balancing | Reduces overload risks |
| Infrastructure Monitoring | Continuous performance reviews | Improves reliability |
| Access Rule Evaluation | Automated compliance checks | Supports governance |
| Data Accuracy Controls | Validation monitoring | Enhances consistency |
| Extraction Scheduling | Controlled automation timing | Maintains stability |
Businesses implementing Ethical Web Crawling and robots.txt Implementation often develop compliance-oriented controls that evaluate request behavior, monitor extraction intensity, and improve operational transparency throughout automated collection processes. These safeguards help maintain ethical automation standards while supporting long-term platform relationships.
At the same time, Understanding robots.txt for Ethical Data Scraping enables organizations to make informed decisions before launching large-scale extraction activities. Businesses reviewing website directives and access expectations typically achieve stronger operational sustainability and improved continuity across competitive digital ecosystems where responsible automation practices are increasingly important for maintaining scalable intelligence workflows.
Developing Sustainable Compliance Practices for Enterprise Intelligence

Modern businesses increasingly depend on structured intelligence systems to improve analytics, competitor monitoring, pricing visibility, and operational decision-making processes. Organizations seeking sustainable automation performance now prioritize governance-driven workflows designed to support ethical digital engagement and responsible extraction management.
Organizations adopting Website Scraping Policies and Compliance Strategies often create scalable governance structures that align technical operations with transparent extraction standards and responsible website interaction practices. These frameworks help enterprises improve operational continuity while minimizing compliance-related disruptions across evolving digital ecosystems.
| Compliance Strategy | Primary Objective | Long-Term Impact |
|---|---|---|
| Governance Documentation | Standardizes extraction practices | Improves accountability |
| Infrastructure Optimization | Maintains stable operations | Enhances scalability |
| Policy Evaluation | Reviews access conditions | Supports adaptability |
| Operational Monitoring | Tracks workflow performance | Reduces interruptions |
| Ethical Oversight | Maintains responsible automation | Strengthens sustainability |
Many companies additionally implement professional Web Scraping Services to support adaptive workflow management, scalable extraction environments, and compliance-focused automation systems. These services contribute to improved operational efficiency while helping organizations maintain structured oversight throughout enterprise intelligence initiatives.
Sustainable extraction environments also depend on continuous infrastructure reviews, controlled automation scheduling, and transparent governance processes. Businesses that regularly evaluate operational performance, monitor compliance standards, and document workflow procedures are generally better positioned to maintain reliable intelligence operations and scalable data acquisition systems across increasingly competitive online environments.
How Web Data Crawler Can Help You?
Modern organizations require scalable extraction systems that balance operational efficiency with responsible compliance management. Businesses implementing Legal Considerations of robots.txt in Data Extraction within their workflows are better positioned to reduce operational conflicts, maintain platform trust, and improve long-term data sustainability across competitive digital environments.
Key support areas include:
- Adaptive crawling configurations for stable extraction performance
- Intelligent scheduling to control traffic distribution
- Automated monitoring for operational consistency
- Structured governance workflows for enterprise scalability
- Risk-focused infrastructure optimization processes
- Transparent reporting for compliance visibility
Organizations seeking long-term automation reliability also benefit from integrating Respecting Crawl-Delay Directives During Scraping into large-scale collection environments. This approach helps maintain responsible digital interactions while supporting sustainable access management and improved operational continuity across evolving online ecosystems.
Conclusion
Responsible automation depends on balancing technical performance with transparent governance practices that support sustainable digital operations. Businesses prioritizing Legal Considerations of robots.txt in Data Extraction are more likely to maintain operational continuity, reduce compliance concerns, and improve long-term scalability across modern intelligence ecosystems.
Organizations adopting Website Scraping Policies and Compliance Strategies can strengthen ethical automation standards while improving governance visibility and reducing operational risks. Contact Web Data Crawler today to build scalable, compliance-focused extraction solutions tailored for responsible business growth and sustainable data intelligence initiatives.