How Headless Browsers vs APIs for Web Scraping Performance Comparison Helps Optimize Data Automation?
May 11

Introduction
Modern businesses depend on real-time information to monitor prices, evaluate competitors, analyze customer behavior, and manage digital operations efficiently. However, extracting large-scale data from dynamic websites often creates performance bottlenecks, especially when automation systems rely on resource-heavy rendering technologies. As websites continue integrating JavaScript frameworks, interactive elements, and anti-bot protections, companies are searching for faster and more stable extraction techniques that improve scalability without compromising accuracy.
Organizations increasingly evaluate Headless Browsers vs APIs for Web Scraping Performance Comparison to determine which method delivers better speed, lower infrastructure consumption, and cleaner data pipelines. While browser-based automation simulates user activity and captures rendered content effectively, API-driven collection reduces bandwidth usage and accelerates processing time significantly.
Businesses integrating a modern Scraping API architecture are also reporting improved concurrency handling and lower cloud computing expenses. These advancements are transforming how enterprises build automated extraction frameworks capable of supporting high-frequency data collection from modern websites and applications while maintaining stability across large-scale automation systems.
Accelerating Large-Scale Data Collection Across Modern Platforms
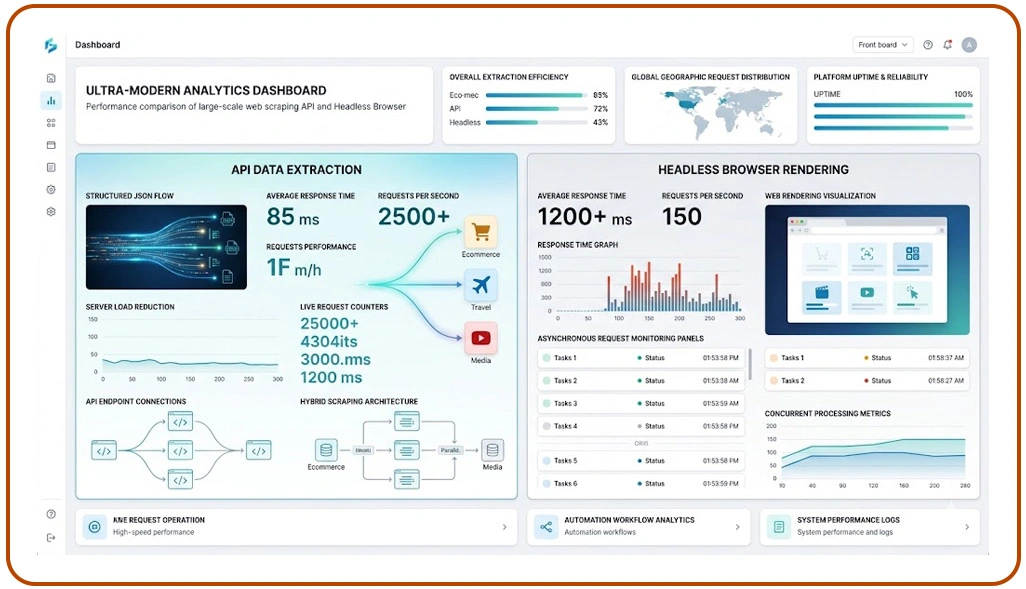
Modern digital platforms rely heavily on JavaScript rendering, asynchronous loading mechanisms, and dynamic content frameworks that significantly affect extraction speed. Businesses managing enterprise automation workflows frequently experience delays when browser-rendered scraping environments attempt to process thousands of requests simultaneously.
Organizations increasingly evaluate Use APIs Instead of Headless Browsers in Scraping because API-driven frameworks retrieve structured information directly from backend endpoints without loading unnecessary interface elements. This approach improves response speed, lowers server strain, and simplifies concurrent processing for large-scale automation systems operating across ecommerce, travel, and media platforms.
Recent industry studies show that API-based extraction methods reduce average execution time by nearly 60% compared to browser-rendered environments. Businesses analyzing the Fastest Methods for Extracting Data From Modern Websites are adopting hybrid architectures where APIs handle structured requests while headless browsers manage interactive workflows selectively.
| Extraction Workflow | Average Processing Time | Infrastructure Usage | Concurrent Scalability |
|---|---|---|---|
| Headless Browser Rendering | 4–8 Seconds | High | Moderate |
| API-Based Extraction | 200–800 Milliseconds | Low | High |
| Hybrid Automation Model | 1–3 Seconds | Medium | High |
Enterprises deploying optimized API architectures report improved throughput, reduced request failures, and lower maintenance efforts across rapidly evolving digital ecosystems. A modern Web Scraping API strategy also improves extraction consistency because structured responses reduce parsing failures and improve downstream analytics integration across enterprise data systems.
Simplifying Infrastructure Management For Enterprise Automation Systems
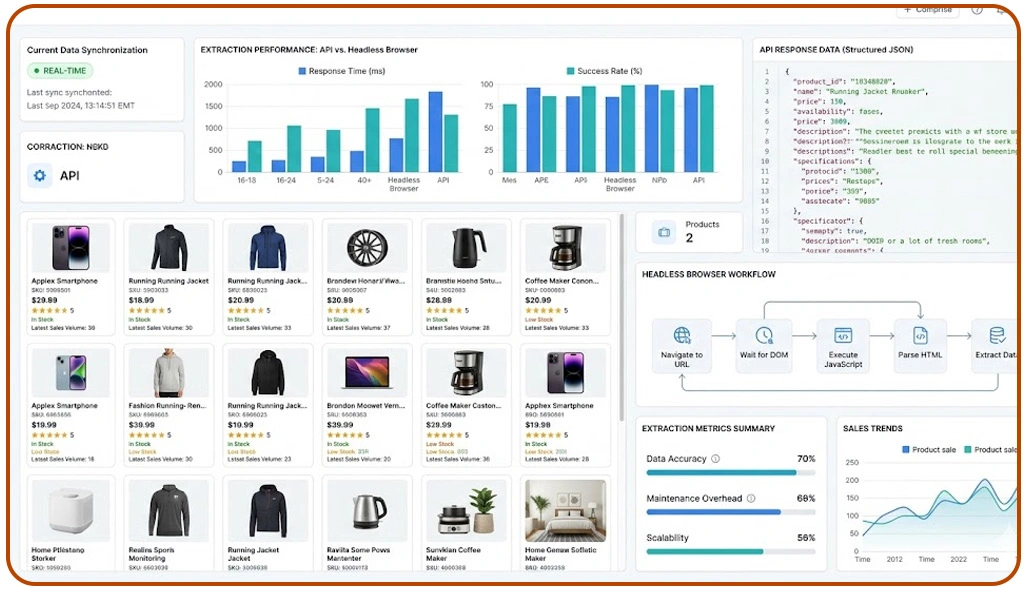
Large-scale extraction environments often face operational difficulties when organizations depend entirely on browser-rendered automation systems. Continuous browser updates, rendering inconsistencies, session management overhead, and anti-bot countermeasures increase maintenance requirements significantly.
Many organizations processing large Web Scraping Datasets now prioritize API-first architectures because structured backend extraction reduces memory usage, simplifies deployment workflows, and improves operational transparency across enterprise automation pipelines. API-based systems eliminate unnecessary rendering dependencies, enabling businesses to scale extraction operations efficiently without aggressively increasing hardware resources.
Research indicates that enterprises implementing Headless Browsers vs APIs for Ecommerce Data Extraction frameworks reduce infrastructure maintenance costs by approximately 40% while improving request stability and concurrent processing performance. Ecommerce businesses particularly benefit because pricing, inventory, and catalog information frequently exist within accessible backend data structures.
| Operational Category | Browser-Based Extraction | API-Driven Extraction |
|---|---|---|
| Memory Consumption | High | Low |
| Infrastructure Scaling | Complex | Simplified |
| Rendering Dependency | Required | Minimal |
| Failure Frequency | Moderate | Low |
| Workflow Stability | Variable | Consistent |
Organizations aiming to Reduce Scraping Costs Using Direct API Extraction Methods increasingly implement distributed extraction environments where APIs manage structured collection while browser automation handles selective user interactions and dynamic rendering requirements.
Strengthening Scalable Automation Strategies For Future Operations
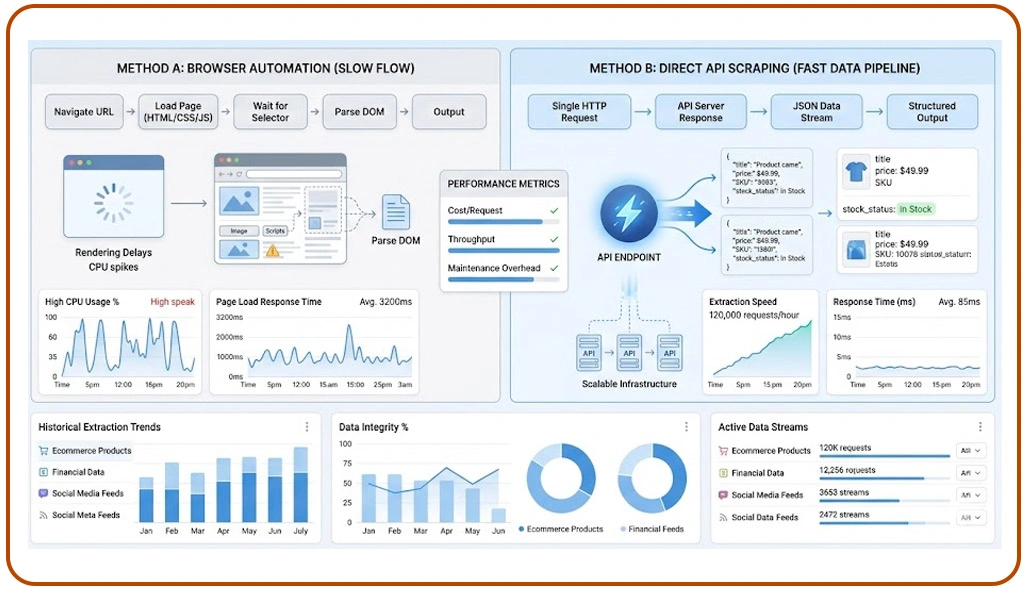
Modern enterprises require automation systems capable of managing rapidly changing digital ecosystems, expanding regional workloads, and increasing extraction demands without compromising performance consistency. Businesses operating across retail, finance, travel, and entertainment industries now prioritize scalable extraction frameworks that balance operational speed, reliability, and infrastructure sustainability for long-term growth.
Organizations increasingly rely on enterprise-grade Web Scraping Services to build adaptive extraction environments capable of supporting millions of concurrent requests across multiple digital sources. These systems combine API-driven collection methods with selective browser automation to improve scalability while maintaining flexibility for interactive workflows and dynamic content rendering.
Industry reports indicate that enterprises modernizing extraction infrastructure improve processing efficiency by nearly 65% while reducing operational disruptions caused by rendering-heavy automation environments. Companies evaluating the Fastest Methods for Extracting Data From Modern Websites continue shifting toward API-centered frameworks because structured extraction improves throughput and simplifies integration into analytics pipelines and business intelligence systems.
| Automation Objective | API-Centered Systems | Browser-Centered Systems |
|---|---|---|
| Processing Efficiency | Excellent | Moderate |
| Interactive Rendering | Limited | Excellent |
| Infrastructure Optimization | High | Medium |
| Concurrent Request Handling | Strong | Moderate |
| Maintenance Complexity | Low | High |
Enterprises implementing Use APIs Instead of Headless Browsers in Scraping workflows are also improving security governance, authentication management, and operational transparency across distributed automation infrastructures. Although browser automation remains essential for selective interaction-heavy scenarios, API-driven architectures increasingly support the foundation of scalable enterprise extraction ecosystems focused on efficiency, stability, and long-term operational growth.
How Web Data Crawler Can Help You?
Organizations must balance speed, infrastructure efficiency, reliability, and long-term operational stability while handling rapidly changing digital environments. Businesses evaluating Headless Browsers vs APIs for Web Scraping Performance Comparison often require customized architectures tailored to their industry workflows, concurrency requirements, and analytics objectives.
Our capabilities include:
- Real-time multi-source extraction frameworks
- Scalable cloud-based automation deployment
- Structured data normalization pipelines
- Intelligent request scheduling systems
- Advanced anti-block management solutions
- High-frequency concurrent extraction handling
Our infrastructure strategies also help enterprises Reduce Scraping Costs Using Direct API Extraction Methods while maintaining consistent performance across high-volume automation workflows and evolving digital ecosystems.
Conclusion
Modern enterprises increasingly depend on efficient automation frameworks to manage large-scale data extraction across dynamic digital ecosystems. Careful evaluation of Headless Browsers vs APIs for Web Scraping Performance Comparison helps organizations improve scalability, optimize processing speed, and reduce operational complexity within enterprise-grade automation systems.
Businesses implementing advanced extraction strategies are also prioritizing Use APIs Instead of Headless Browsers in Scraping to simplify infrastructure management and improve long-term workflow stability. Contact Web Data Crawler today to build customized automation solutions designed for scalable, high-performance data intelligence operations.