How Do Experts Handle JavaScript-Heavy Websites in Web Scraping Across 10K+ Dynamic Pages Worldwide?
May 11

Introduction
Modern digital platforms increasingly depend on JavaScript frameworks to load content dynamically, personalize interfaces, and manage user interactions in real time. From eCommerce marketplaces to travel portals and social media dashboards, websites now deliver data through asynchronous rendering techniques that traditional crawlers often fail to interpret correctly.
Advanced browser automation tools, rotating proxies, distributed queues, and intelligent rendering systems help organizations Handle JavaScript-Heavy Websites in Web Scraping without disrupting extraction quality. Research indicates that nearly 67% of enterprise-level web platforms now rely on client-side rendering technologies, making dynamic content processing an essential requirement for modern data collection strategies.
Companies also integrate specialized Scraping API environments to reduce rendering overhead and automate browser execution at scale. These systems simplify session handling, CAPTCHA management, and asynchronous page loading challenges. The result is faster access to accurate business intelligence, competitive pricing insights, and structured datasets essential for analytics-driven decision-making.
Building Reliable Rendering Systems For Large Dynamic Platforms
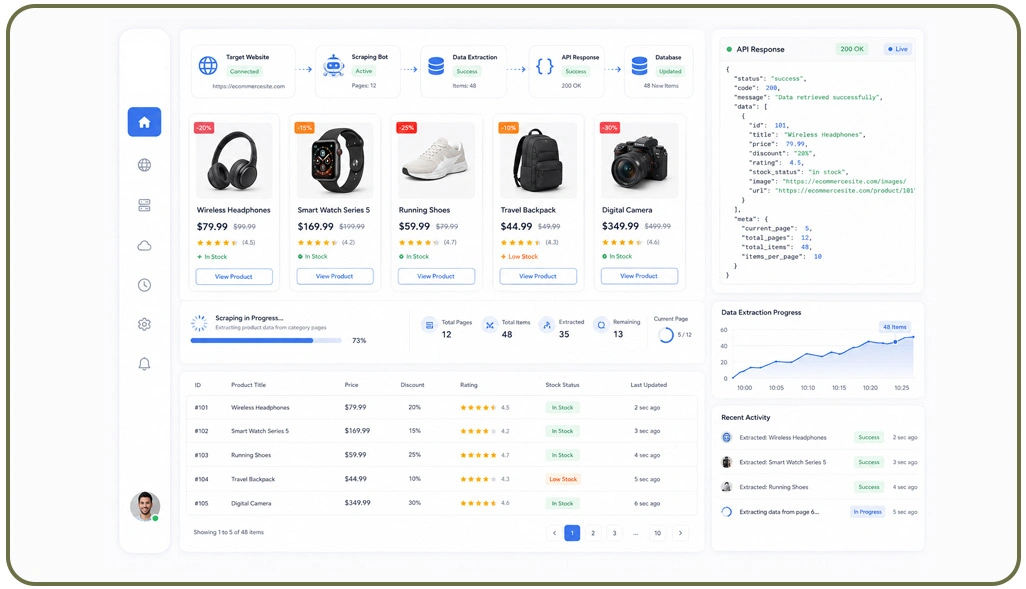
Modern websites increasingly rely on JavaScript frameworks that load content dynamically after the initial page request. This shift creates significant challenges for enterprises collecting large-scale data because standard crawlers cannot easily process asynchronous rendering workflows. Businesses handling international extraction operations therefore implement browser-based automation systems capable of simulating real user interactions across thousands of pages daily.
Engineering teams commonly deploy headless browsers such as Playwright and Puppeteer to render page elements completely before extraction begins. Many organizations additionally integrate specialized Web Scraping API environments to simplify browser orchestration, session handling, and dynamic content processing. These APIs reduce infrastructure complexity while improving workflow stability for enterprise-scale operations.
Another important strategy involves monitoring asynchronous requests to Scrape AJAX-Loaded Ecommerce Websites more efficiently. Instead of depending entirely on rendered HTML, experts analyze network traffic directly to retrieve cleaner structured outputs with lower resource consumption. Distributed execution clusters improve performance by balancing traffic across multiple regions while minimizing latency during extraction operations.
| Dynamic Rendering Challenges | Technical Solutions |
|---|---|
| Client-side page rendering | Browser automation frameworks |
| Infinite content loading | Scroll event simulation |
| Session authentication | Persistent cookie handling |
| AJAX-driven product listings | Network request interception |
| High request volumes | Distributed browser clusters |
| Rendering failures | Automated monitoring systems |
Advanced extraction architectures continue evolving as websites become more interactive. Organizations investing in scalable rendering infrastructure maintain stronger operational consistency while supporting large-scale analytics and competitive intelligence initiatives worldwide.
Detecting Hidden Data Flows Inside Interactive Applications
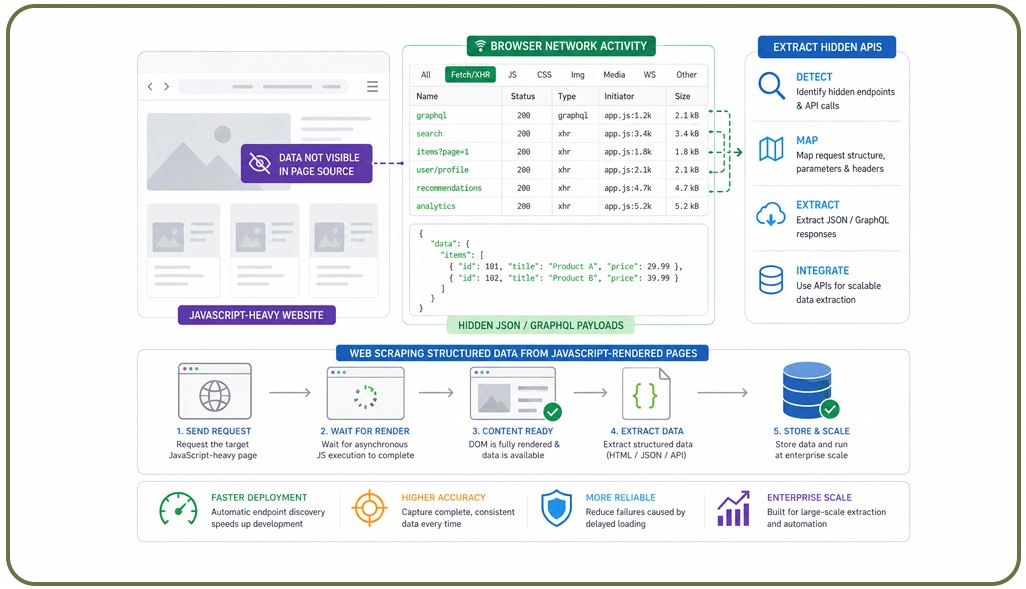
Modern digital platforms often hide valuable information behind asynchronous API requests instead of displaying data directly within visible page elements. This architecture improves frontend performance but creates substantial challenges for organizations conducting enterprise-scale extraction projects. As a result, engineering teams increasingly focus on analyzing hidden communication layers that transfer structured data during user interactions.
One widely adopted strategy involves monitoring browser network activity to identify JSON payloads, GraphQL requests, and backend service endpoints. Specialized automation systems now help organizations Extract Hidden APIs From JavaScript-Heavy Websites without manually inspecting every frontend interaction. Intelligent request mapping frameworks automatically detect hidden endpoints, significantly accelerating deployment timelines for large-scale scraping projects.
Another important practice includes Web Scraping Structured Data From JavaScript-Rendered Pages using synchronization logic that captures content only after asynchronous rendering processes complete successfully. This approach improves extraction consistency while reducing incomplete or corrupted outputs caused by delayed frontend loading events.
| Hidden Extraction Methods | Operational Benefits |
|---|---|
| API request interception | Faster extraction speed |
| GraphQL endpoint analysis | Cleaner structured outputs |
| Network traffic monitoring | Reduced rendering overhead |
| Automated request discovery | Faster deployment cycles |
| JSON payload extraction | Improved data consistency |
| Response validation systems | Better operational stability |
Businesses also increasingly depend on structured Web Scraping Datasets generated from dynamic applications for forecasting, pricing analysis, and market intelligence reporting. Structured outputs collected directly from APIs generally provide cleaner and more reliable information compared to traditional HTML parsing approaches.
Scaling Global Infrastructure For Continuous Data Collection Operations

Large-scale extraction projects involving thousands of interactive pages require sophisticated infrastructure capable of balancing rendering workloads, maintaining uptime, and adapting to evolving anti-bot systems. Enterprises operating across multiple international regions therefore prioritize cloud-native architectures that support stable performance under high-volume extraction conditions.
Modern organizations commonly deploy distributed browser environments that process workloads across geographically diverse servers. Many businesses additionally implement Scalable Scraping Pipelines for Dynamic Web Applications to coordinate browser execution, queue management, and asynchronous task processing across distributed infrastructures.
Real-time diagnostics also play an important role in maintaining extraction consistency. Monitoring systems continuously track browser crashes, rendering delays, request failures, and response anomalies. To reduce infrastructure maintenance complexity, enterprises frequently collaborate with specialized Web Scraping Services providers capable of managing proxy rotation, rendering environments, and traffic optimization systems.
| Infrastructure Components | Business Advantages |
|---|---|
| Distributed browser networks | Improved global performance |
| Cloud-native orchestration | Automated scaling efficiency |
| Queue-based task systems | Higher processing throughput |
| Real-time monitoring tools | Faster issue detection |
| Proxy management systems | Better request stability |
| Automated recovery workflows | Reduced operational downtime |
Scalable infrastructure continues serving as the foundation for reliable enterprise extraction workflows. Organizations investing in adaptive cloud-based architectures maintain stronger operational resilience while supporting continuous data collection across highly dynamic digital ecosystems worldwide.
How Web Data Crawler Can Help You?
Modern enterprises working with dynamic digital platforms require highly adaptive extraction systems capable of processing complex rendering environments efficiently. Businesses aiming to improve operational intelligence often need advanced frameworks that can reliably Handle JavaScript-Heavy Websites in Web Scraping across large-scale international datasets while maintaining speed, accuracy, and infrastructure stability.
Our Core Capabilities:
- Advanced browser rendering for dynamic platforms
- Distributed extraction across global infrastructures
- Intelligent proxy and session management
- Real-time monitoring and automated recovery systems
- API-driven extraction workflows for structured outputs
- Scalable deployment architecture for enterprise operations
Our experts also support businesses seeking to Extract Hidden APIs From JavaScript-Heavy Websites for faster and cleaner data acquisition workflows. These optimized extraction strategies reduce infrastructure overhead while improving large-scale scraping efficiency for analytics, market intelligence, and competitive monitoring initiatives.
Conclusion
Modern enterprises increasingly depend on scalable browser automation, intelligent rendering frameworks, and distributed extraction systems to process dynamic online platforms efficiently. Organizations that successfully Handle JavaScript-Heavy Websites in Web Scraping achieve faster access to structured intelligence while improving operational scalability across international data ecosystems.
Businesses also continue investing in advanced methods to Scrape AJAX-Loaded Ecommerce Websites for improved pricing analysis, product monitoring, and competitive intelligence initiatives. Contact Web Data Crawler today to build enterprise-ready scraping infrastructures designed for large-scale dynamic web extraction workflows worldwide.