How to Fix Duplicate and Inconsistent Data in Web Scraping for High-Quality and Accurate Data Output?
May 05

Introduction
In today's data-driven ecosystem, organizations depend heavily on web scraping to collect structured insights from multiple digital sources. However, the biggest challenge arises when scraped datasets contain duplication and inconsistencies that compromise reliability. Businesses investing in Market Research often find that inaccurate data leads to flawed analytics, poor forecasting, and ineffective strategic decisions.
This is why it becomes essential to Fix Duplicate and Inconsistent Data in Web Scraping to ensure clean, usable, and actionable datasets. Duplicate entries can emerge due to repeated crawling cycles, overlapping sources, or improper data merging processes. Meanwhile, inconsistencies occur when scraped data varies in format, structure, or completeness.
These issues collectively reduce the value of extracted information and increase the complexity of downstream processing. Organizations must implement robust validation frameworks, intelligent deduplication mechanisms, and standardized data pipelines to maintain data integrity. This blog explores key challenges and practical solutions to overcome duplication and inconsistency issues in web scraping workflows, ensuring accurate outputs and long-term data reliability.
Analyzing Core Reasons Behind Data Duplication and Structural Inconsistencies
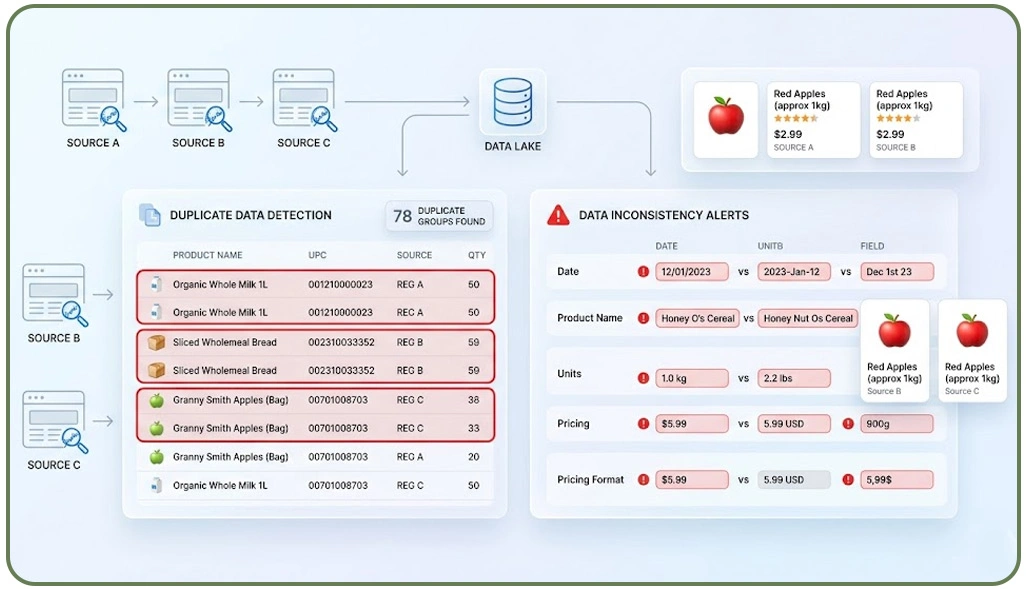
Understanding the root causes of duplication and inconsistency is essential before implementing corrective measures in any data extraction workflow. One of the most frequently asked questions in this domain is Why Does Web Scraping Produce Duplicate Data?, which typically arises due to repeated crawl cycles, dynamic content updates, and lack of unique identifiers across sources.
In large-scale environments such as Enterprise Web Crawling, duplication becomes more prominent when multiple pages contain overlapping information. For example, identical product listings may appear under different categories or regions, creating redundancy during aggregation. Without proper filtering mechanisms, these duplicates inflate dataset size and reduce analytical efficiency.
Additionally, inconsistencies arise when websites follow varied structures and formatting standards. Differences in date formats, naming conventions, and units of measurement create challenges in standardizing data for analysis. Such issues contribute significantly to Web Scraping Data Quality Issues for Accurate Data, making it difficult to derive reliable insights.
Key Causes and Their Impact:
| Issue Type | Cause | Impact |
|---|---|---|
| Duplicate Entries | Repeated crawl cycles | Increased storage load |
| Format Inconsistency | Diverse source structures | Complex normalization |
| Missing Attributes | Partial extraction | Data gaps |
| Overlapping Records | Multi-source scraping | Redundant entries |
Addressing these structural challenges requires careful pipeline design and proactive identification of duplication points to ensure consistent and high-quality datasets.
Applying Structured Validation and Deduplication Methods for Cleaner Outputs
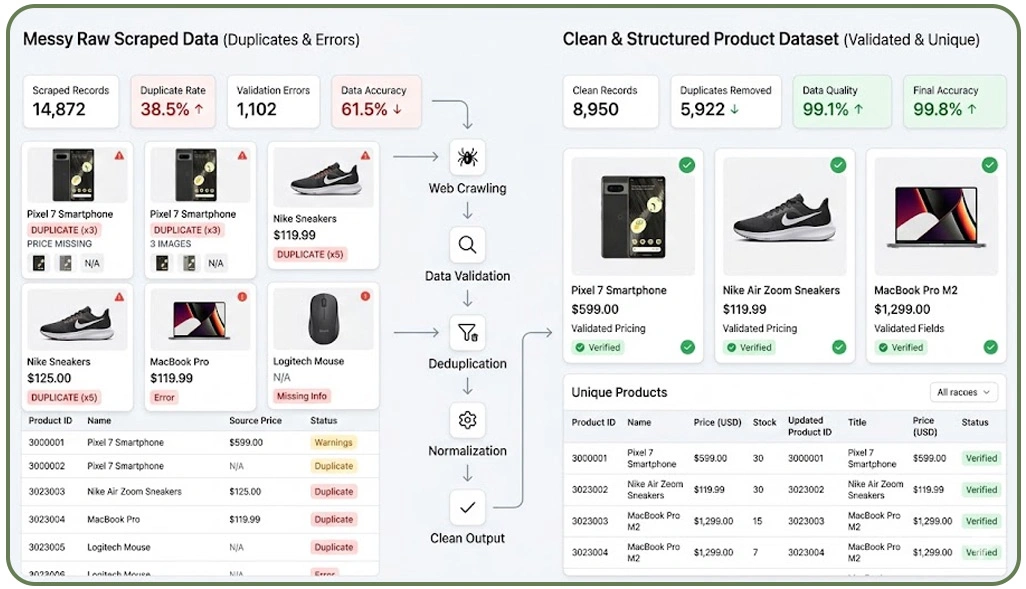
Ensuring clean and structured datasets requires implementing systematic validation and deduplication techniques within the scraping workflow. One of the most critical aspects is Data Validation in Web Scraping for Accuracy, which ensures that incoming data adheres to predefined quality standards before being processed further.
A well-configured Web Crawler plays a significant role in minimizing duplication by applying rules that identify and filter repeated entries. This can be achieved using unique identifiers such as URLs, product IDs, or timestamps, which help distinguish records effectively. By integrating validation rules directly into the crawling process, businesses can prevent redundant data from entering their systems.
Additionally, addressing Scraping Pipeline Data Errors for Quality Assurance ensures that validation checkpoints are implemented at every stage, reducing the risk of inconsistencies and improving overall data reliability. Without normalization, datasets remain fragmented and difficult to analyze.
Effective Deduplication Techniques:
| Technique | Description | Benefit |
|---|---|---|
| Hashing | Assign unique keys to records | Faster duplicate detection |
| Attribute Matching | Compare key fields | Higher accuracy |
| Rule-Based Filters | Apply validation logic | Reduced redundancy |
| Format Standardization | Normalize data fields | Consistency |
Automation tools such as Python Remove Duplicates From Scraped Data scripts are widely used to streamline the cleaning process. These tools scan datasets and remove repeated entries efficiently. Without normalization, datasets remain fragmented and difficult to analyze.
Enhancing Data Pipelines Through Automation and Continuous Monitoring Systems
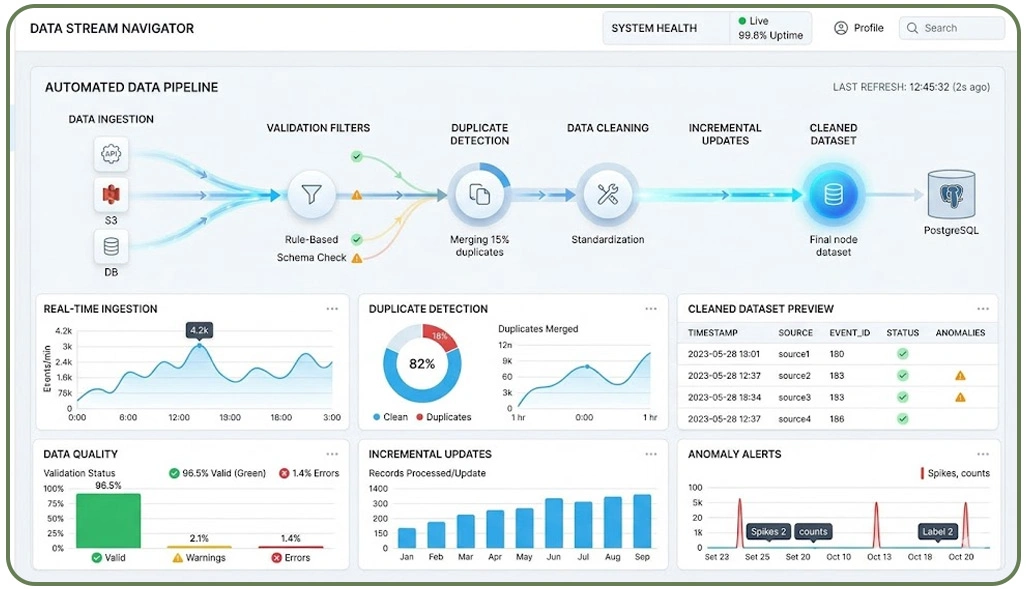
Modern data extraction workflows demand advanced automation and monitoring systems to maintain consistency and reliability. As datasets grow in volume and complexity, manual intervention becomes inefficient, making automation a critical component of optimized pipelines.
Technologies like Live Crawler Services enable real-time data extraction while applying validation rules instantly. This approach minimizes duplication and ensures that only updated or relevant data is captured. Real-time processing is particularly useful when dealing with frequently changing web content.
Another effective strategy is incremental data extraction, where systems collect only newly added or modified records instead of reprocessing entire datasets. This significantly reduces redundancy and improves operational efficiency. Dashboards and alert mechanisms help detect unusual patterns, missing values, or formatting issues in real time.
Automation Strategies for Data Consistency:
| Strategy | Function | Outcome |
|---|---|---|
| Incremental Extraction | Capture new data only | Reduced duplication |
| Real-Time Validation | Immediate quality checks | Improved accuracy |
| Automated Alerts | Detect anomalies early | Faster resolution |
| Data Versioning | Track changes | Better consistency |
Continuous monitoring systems also play a vital role in identifying inconsistencies. By combining automation with proactive monitoring, businesses can maintain structured and reliable datasets. This ensures that data pipelines remain efficient, scalable, and capable of delivering accurate insights without unnecessary redundancy or inconsistency.
How Web Data Crawler Can Help You?
Achieving consistent and reliable datasets requires expertise, advanced tools, and structured workflows. Many organizations struggle with fragmented pipelines and unreliable outputs until they implement solutions designed to Fix Duplicate and Inconsistent Data in Web Scraping effectively.
Key Capabilities Include:
- Advanced duplicate detection systems.
- Intelligent data structuring frameworks.
- Automated validation checkpoints.
- Scalable crawling architecture.
- Real-time monitoring and alerts.
- Custom data transformation solutions.
These capabilities ensure that businesses receive clean and actionable datasets without manual intervention. In addition, our solutions address Web Scraping Data Quality Issues for Accurate Data, ensuring that every dataset meets high standards of reliability and usability.
Conclusion
Data accuracy is not optional in today's competitive landscape. Implementing validation, automation, and monitoring strategies helps Fix Duplicate and Inconsistent Data in Web Scraping while ensuring reliable outputs for analytics and decision-making.
Addressing challenges such as Data Validation in Web Scraping for Accuracy enables organizations to transform raw data into valuable insights that drive growth. Ready to improve your data quality and streamline your scraping processes? Connect with Web Data Crawler today and build a smarter, more reliable data pipeline.