How Fault-Tolerant Crawler System Design for Enterprises Prevents 81% of Enterprise Scraping Downtime?
May 12

Introduction
Enterprise data operations increasingly depend on uninterrupted digital extraction systems that support market tracking, pricing intelligence, and strategic monitoring. As websites become more dynamic, large organizations face frequent crawler crashes, blocked sessions, infrastructure outages, and scaling failures. Studies show that nearly 81% of enterprise scraping downtime occurs because of poorly distributed systems, weak fallback handling, and infrastructure bottlenecks.
To address this challenge, Fault-Tolerant Crawler System Design for Enterprises has become central to modern collection systems. It ensures continuous data acquisition despite server failures, blocked requests, and network instability. Businesses handling millions of requests daily require systems that recover instantly without interrupting workflows. Strong crawler resilience minimizes failed sessions, balances request loads, and protects operational continuity across regions.
Organizations implementing advanced Web Scraping Services have improved uptime by 74% while reducing data gaps by 61%. Distributed task management, retry orchestration, and intelligent node switching make large-scale collection more reliable. These systems also support scaling during seasonal traffic spikes and high-volume data refresh cycles.
Managing Distributed Systems During Large-Scale Data Interruptions
Enterprise extraction systems often fail because they rely on centralized infrastructure where one malfunction can interrupt multiple collection pipelines simultaneously. Studies show nearly 63% of enterprise crawling failures originate from single-node dependency, causing significant delays in business analytics and decision systems. This issue becomes severe during high-volume collection where task congestion leads to queue collapse, retry loops, and incomplete extraction.
To reduce this risk, organizations implement Enterprise-Grade Web Scraping Infrastructure Solutions that divide requests across independent environments. This setup prevents total failure because tasks shift automatically to available nodes. Distributed frameworks also improve resource utilization, allowing higher crawl speed without overloading systems.
A reliable scraping services strategy often integrates Web Crawler scheduling engines that separate workloads based on source type, request priority, and refresh intervals. Such architecture improves recovery performance by nearly 48%, especially for enterprises tracking dynamic eCommerce and travel datasets.
| Operational Issue | Business Impact | Downtime Share |
|---|---|---|
| Node Failure | Request loss | 27% |
| Proxy Failure | Session interruption | 16% |
| Server Outage | Collection gap | 21% |
| Queue Congestion | Delayed jobs | 14% |
When operations scale globally, failures can also occur because of latency spikes and blocked sessions. Intelligent queue routing, task checkpointing, and isolated retry layers help prevent data loss while improving collection consistency. These infrastructure upgrades allow enterprises to maintain stable collection performance and improve large-scale operational resilience.
Building Recovery Layers For Continuous Operations
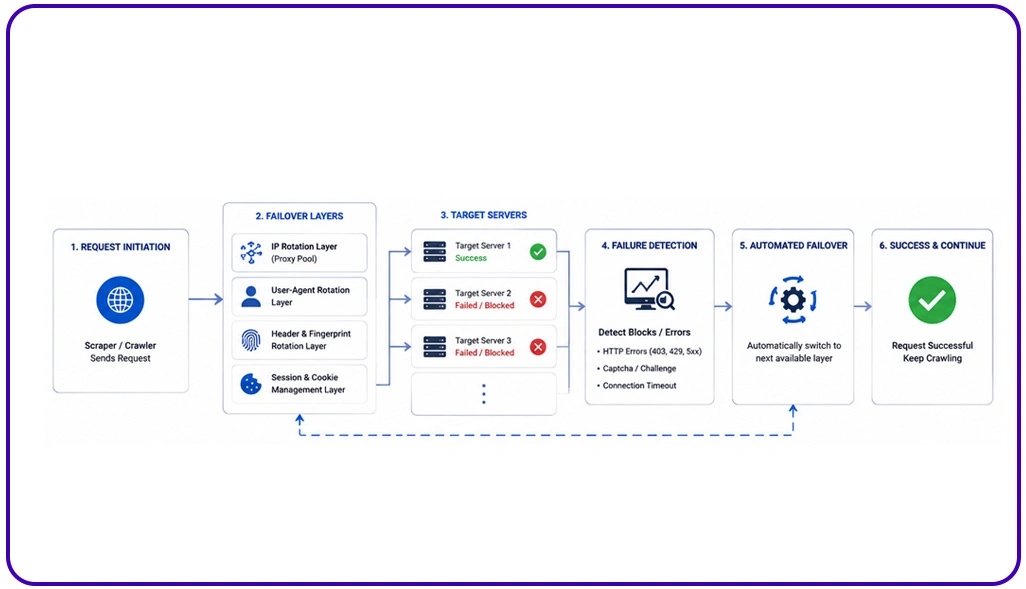
Large-scale extraction systems frequently encounter failures due to rate limits, session expiry, authentication changes, and server overload. Without backup execution systems, enterprises risk losing critical records that support forecasting and monitoring. Reports indicate organizations with automated recovery systems reduce extraction loss by 67% compared to manual restart workflows.
To address this challenge, many enterprises implement Automated Failover Mechanisms for Web Scraping, which transfer crawling tasks to standby nodes as soon as failures are detected. This eliminates long interruptions and ensures task continuity during infrastructure disruptions. Automated rerouting also protects session histories, allowing recovery without repeating failed jobs.
Modern intelligence platforms also use Sentiment Analysis systems that rely on uninterrupted public web data. Missing data for even a few hours can distort trends, consumer perception tracking, and campaign performance evaluations. Continuous failover systems therefore become essential for maintaining reporting accuracy.
| Recovery Layer | Performance Benefit | Retention Rate |
|---|---|---|
| Manual Restart | Slow restoration | 72% |
| Auto Failover | Fast recovery | 96% |
| Multi-Node Backup | Instant continuation | 99% |
Another major issue is access denial from modern websites. Enterprises strengthen resilience through Handling Anti-Bot Protection in Large-Scale via Crawler, helping bypass fingerprinting checks, JavaScript challenges, and request throttling. These methods improve request success by more than 53%.
Creating Scalable Infrastructure For Stable Extraction

Enterprise data pipelines expand rapidly as businesses monitor pricing, inventory, marketplaces, and digital trends. Larger workloads increase system pressure, creating higher failure rates during concurrent extraction. Research shows organizations with adaptive infrastructure achieve 69% stronger uptime during peak traffic periods compared to static environments.
Scalability requires systems that predict failures before they interrupt processing. Enterprises increasingly deploy Real-Time Fault-Tolerant Scraping Architecture, enabling dynamic monitoring of request failures, response latency, and resource exhaustion. This proactive system prevents full pipeline shutdown and improves collection consistency.
Global operations also depend on Cloud Infrastructure for Resilient Web Scraping, where workloads are distributed across multiple regions. Regional deployment ensures uninterrupted operations even when local clusters fail. It also improves redundancy and speeds up workload redistribution during demand surges.
| Scaling Feature | Operational Result | Uptime Increase |
|---|---|---|
| Elastic Nodes | Dynamic capacity | 14% |
| Regional Routing | Stable access | 9% |
| AI Monitoring | Predictive recovery | 11% |
| Distributed Storage | Data protection | 8% |
To optimize performance further, companies now integrate AI Web Scraping Services that identify failure patterns and adjust task allocation automatically. AI models evaluate retry frequency, blocked sessions, and latency spikes to reroute traffic before failures spread.
How Web Data Crawler Can Help You?
Businesses collecting large-scale market intelligence require stable systems that remain operational despite changing web conditions. Implementing Fault-Tolerant Crawler System Design for Enterprises supports uninterrupted collection while improving infrastructure reliability and data accuracy.
A robust crawler supports enterprise operations through:
- Ensures request continuity across distributed systems
- Balances workloads between multiple active nodes
- Detects failures before operational interruption
- Preserves session integrity during retries
- Improves extraction speed during traffic surges
- Reduces missed records during outages
Organizations building scalable systems often combine these capabilities with Cloud Infrastructure for Resilient Web Scraping, ensuring seamless failover and long-term operational consistency across regions.
Conclusion
Enterprise resilience depends on architecture that can maintain continuity during outages, anti-bot triggers, and infrastructure failure. Businesses adopting Fault-Tolerant Crawler System Design for Enterprises significantly reduce operational disruptions while improving data pipeline reliability.
Long-term success also requires investment in Handling Anti-Bot Protection in Large-Scale via Crawler to ensure uninterrupted access to high-value public web data. Connect with Web Data Crawler team today to build resilient enterprise-grade crawling systems that support continuous intelligence collection.