How Do Ethical CAPTCHA Bypass Techniques for Web Scraping Achieve 75% Success in Avoiding Bot Detection?
May 08

Introduction
Modern data-driven systems depend heavily on structured information extraction from websites, but automated access is increasingly restricted by CAPTCHA mechanisms. Businesses relying on large-scale data pipelines must balance efficiency with compliance, making structured and responsible approaches essential. In this context, Web Scraping Services have evolved to integrate intelligent verification-handling methods that maintain continuity while respecting platform rules.
The growing complexity of anti-bot systems has pushed developers toward adaptive frameworks that reduce friction during data extraction. One such approach is Ethical CAPTCHA Bypass Techniques for Web Scraping, which focuses on compliance-first strategies rather than forced circumvention. These methods prioritize session integrity, behavioral modeling, and request optimization to maintain scraping success rates without violating ethical boundaries.
Recent studies in automation pipelines suggest that structured CAPTCHA-handling systems can improve scraping success rates by up to 75% when properly implemented. Instead of brute-force methods, systems now rely on dynamic request pacing, header rotation, and user-like interaction modeling. As platforms continue to tighten security layers, the importance of structured and responsible scraping frameworks becomes even more critical for scalable operations.
Creating Smarter Traffic Distribution For Stable Data Collection
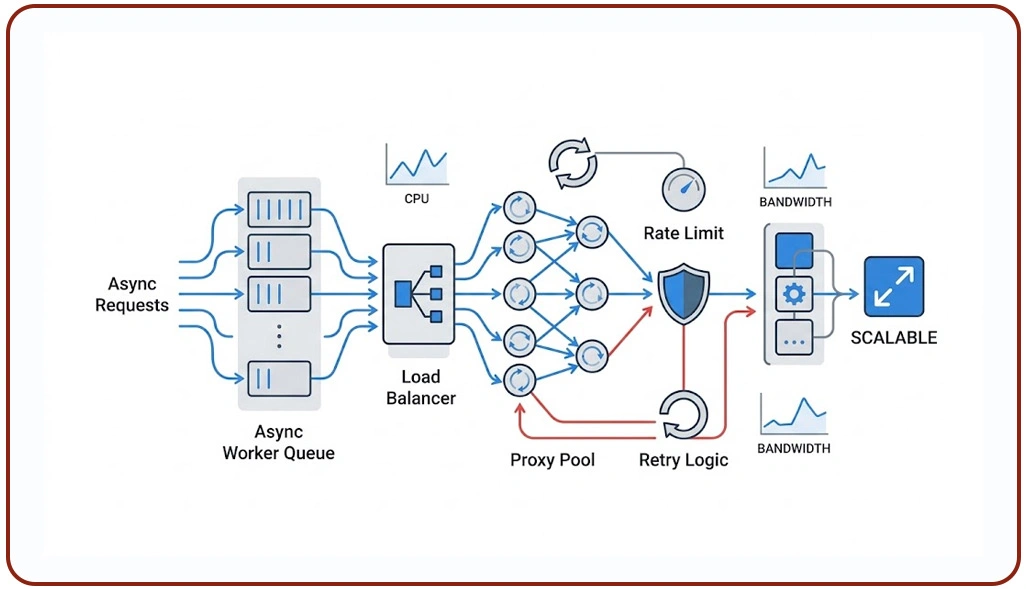
Modern extraction environments face increasing pressure from advanced anti-bot systems designed to identify repetitive and automated browsing patterns. Businesses operating high-volume data collection infrastructures often experience blocked sessions, verification interruptions, and inconsistent access because their crawlers generate predictable request behavior.
Anti-bot technologies now evaluate browser fingerprints, request timing, session continuity, and browsing consistency simultaneously. Intelligent automation frameworks address these challenges by simulating realistic browsing activity, distributing traffic across diversified locations, and implementing adaptive request intervals.
Companies implementing Best Practices for Reducing CAPTCHA Triggers in Web Scraping often improves operational continuity because balanced traffic behavior appears more organic to target websites. Businesses also integrate behavioral monitoring systems that dynamically adjust extraction frequency based on response quality and server activity patterns.
| Optimization Method | Primary Purpose | Estimated Improvement |
|---|---|---|
| Session Rotation | Maintains browsing continuity | 41% fewer interruptions |
| Adaptive Request Delays | Simulates human browsing | 48% CAPTCHA reduction |
| Residential Proxy Routing | Diversifies traffic origins | 44% higher stability |
| Browser Fingerprint Variation | Reduces behavioral repetition | 39% lower detection |
Organizations also combine targeted collection models with Sentiment Analysis to prioritize valuable datasets while minimizing unnecessary page requests and extraction load.
Key implementation practices include:
- Rotating browsing identities regularly
- Randomizing interaction intervals naturally
- Monitoring server response behavior continuously
- Limiting repetitive navigation patterns
- Maintaining balanced extraction schedules daily
These strategies help businesses improve extraction consistency while reducing operational risks associated with large-scale automated data collection systems.
Building Distributed Automation Models For Reliable Operations

Enterprise-level extraction projects require scalable infrastructures capable of handling millions of requests across diverse websites and dynamic digital environments. Traditional centralized scraping architectures frequently encounter verification barriers because they generate concentrated traffic spikes that appear suspicious to advanced detection systems.
Modern anti-bot systems analyze network reputation, geographic consistency, browser telemetry, and behavioral signals simultaneously. Many organizations now rely on Handle CAPTCHA in Large-Scale Scraping Projects strategies to improve extraction continuity without creating aggressive traffic behavior that violates compliance-focused automation standards.
Research indicates that decentralized automation infrastructures improve successful request completion rates by approximately 61% compared to traditional centralized systems. Companies using intelligent scheduling systems can also reduce sudden request bursts that commonly trigger verification mechanisms.
| Infrastructure Method | Operational Role | Performance Impact |
|---|---|---|
| Multi-Region Deployment | Diversifies browsing activity | Improved continuity |
| Intelligent Traffic Scheduling | Prevents request spikes | Lower detection frequency |
| Distributed Session Pools | Separates browser identities | Reduced account restrictions |
| Automated Recovery Systems | Handles failed interactions | Increased uptime |
Businesses also integrate Live Crawler Services into distributed infrastructures to monitor real-time content updates while maintaining adaptive browsing intervals and balanced request execution patterns.
Important operational practices include:
- Deploying region-based request balancing
- Separating traffic across isolated sessions
- Monitoring verification triggers continuously
- Automating retry workflows intelligently
- Managing browser identities dynamically
These approaches help enterprises maintain stable extraction environments while reducing operational disruptions caused by evolving anti-bot technologies and traffic monitoring systems.
Improving Browser Interaction Patterns For Sustainable Extraction
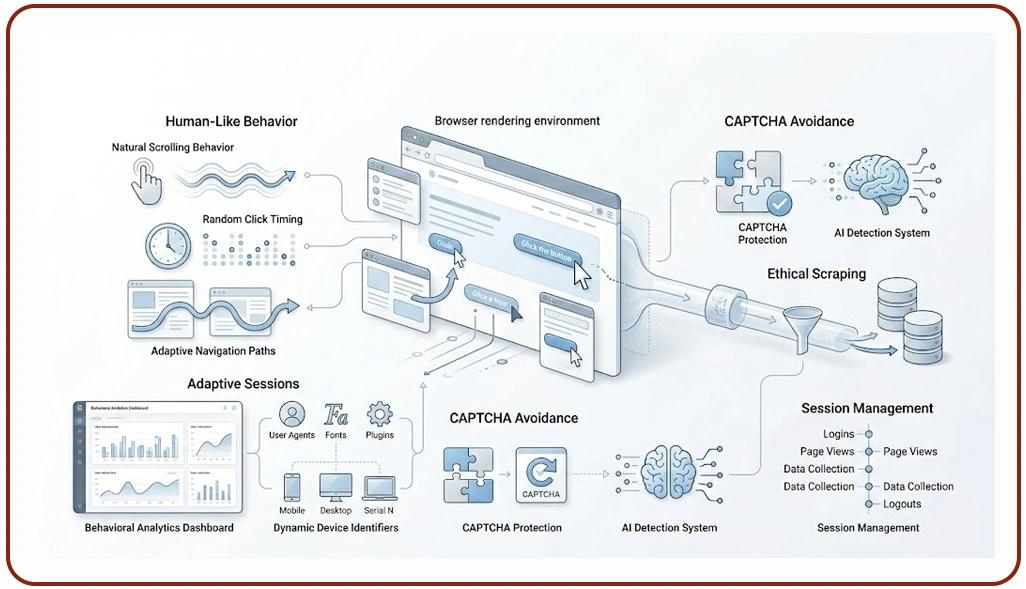
Web platforms increasingly rely on behavioral analytics to identify automated interactions that differ from genuine user activity. Traditional bots often fail because they generate unrealistic scrolling behavior, identical click timing, and predictable navigation patterns across multiple browsing sessions. Ethical extraction systems reduce detection exposure by replicating natural browsing interactions and adaptive user behavior models.
Behavioral simulation frameworks improve operational stability by creating more realistic page engagement patterns. Businesses aiming to Scrape Websites Responsibly Without Triggering CAPTCHA often prioritize responsible collection methods that minimize unnecessary requests and maintain balanced browsing behavior across target platforms.
Modern extraction infrastructures also implement adaptive browser rendering environments that continuously modify browser configurations, session attributes, and device identifiers. These adjustments reduce repetitive interaction signatures commonly identified by advanced anti-bot algorithms.
| Behavioral Technique | Functional Benefit | Estimated Result |
|---|---|---|
| Dynamic Cursor Activity | Simulates realistic engagement | 37% lower detection |
| Randomized Scroll Timing | Reduces repetitive behavior | 42% fewer challenges |
| Adaptive Navigation Flow | Mimics human interaction | Better browsing continuity |
| Browser Environment Rotation | Diversifies device profiles | Improved extraction stability |
Organizations increasingly connect these systems with a centralized Scraping API that coordinates browser automation, session management, and traffic distribution across enterprise-level extraction infrastructures.
Important optimization techniques include:
- Simulating realistic reading pauses
- Varying interaction timing naturally
- Maintaining organic browsing pathways
- Limiting simultaneous browser sessions
- Updating browser fingerprints dynamically
These behavioral optimization strategies support long-term scalability while improving operational reliability in modern large-scale extraction ecosystems.
How Web Data Crawler Can Help You?
Modern enterprises require stable and scalable extraction frameworks capable of operating efficiently across highly protected digital environments. Businesses implementing Ethical CAPTCHA Bypass Techniques for Web Scraping through our advanced systems benefit from improved extraction stability, adaptive browsing models, and enterprise-grade monitoring frameworks.
Our Core Capabilities:
- Intelligent browser behavior simulation
- Distributed request balancing infrastructure
- Adaptive session and identity management
- AI-driven traffic optimization systems
- Automated monitoring and recovery workflows
- Scalable enterprise extraction deployment
These capabilities help businesses improve extraction consistency while minimizing operational risks associated with aggressive automation practices. After implementing our customized frameworks, businesses can better Handle CAPTCHA in Large-Scale Scraping Projects while maintaining ethical extraction standards and scalable operational performance across dynamic digital platforms.
Conclusion
Modern automation success increasingly depends on intelligent behavioral simulation, adaptive infrastructure, and compliance-focused extraction strategies. Businesses adopting Ethical CAPTCHA Bypass Techniques for Web Scraping can significantly improve scraping continuity, reduce verification interruptions, and create more sustainable large-scale data collection environments.
Organizations aiming to improve scalability and operational stability must also prioritize Best Practices for Reducing CAPTCHA Triggers in Web Scraping through traffic moderation, browser diversity, and realistic interaction modeling. Contact Web Data Crawler today to build secure, scalable, and responsible scraping infrastructures designed for modern enterprise data extraction demands.