What Drives E-Commerce Data Entity Resolution Issues in Web Scraping Across Large-Scale Data Pipelines?
May 06

Introduction
Modern digital commerce ecosystems rely heavily on structured intelligence extracted from massive datasets. However, when businesses perform Web Scraping Ecommerce Data, they often encounter inconsistencies that disrupt downstream analytics. One of the most persistent challenges lies in resolving identical entities—products, brands, or listings—that appear differently across platforms.
These discrepancies become more severe as data pipelines scale, especially when aggregating from marketplaces, review platforms, and retailer websites. Even minor inconsistencies, such as differences in SKU formats or product titles, can result in fragmented insights. This directly impacts pricing intelligence, inventory planning, and competitive benchmarking.
Addressing E-Commerce Data Entity Resolution Issues in Web Scraping requires a blend of rule-based systems and intelligent automation. Organizations must refine how they identify, match, and unify entities across diverse sources while maintaining data freshness and accuracy. Understanding what drives these issues is the first step toward building resilient, scalable data pipelines that deliver consistent and actionable retail intelligence.
Understanding Structural Inconsistencies Across Multi-Platform Product Data Sources
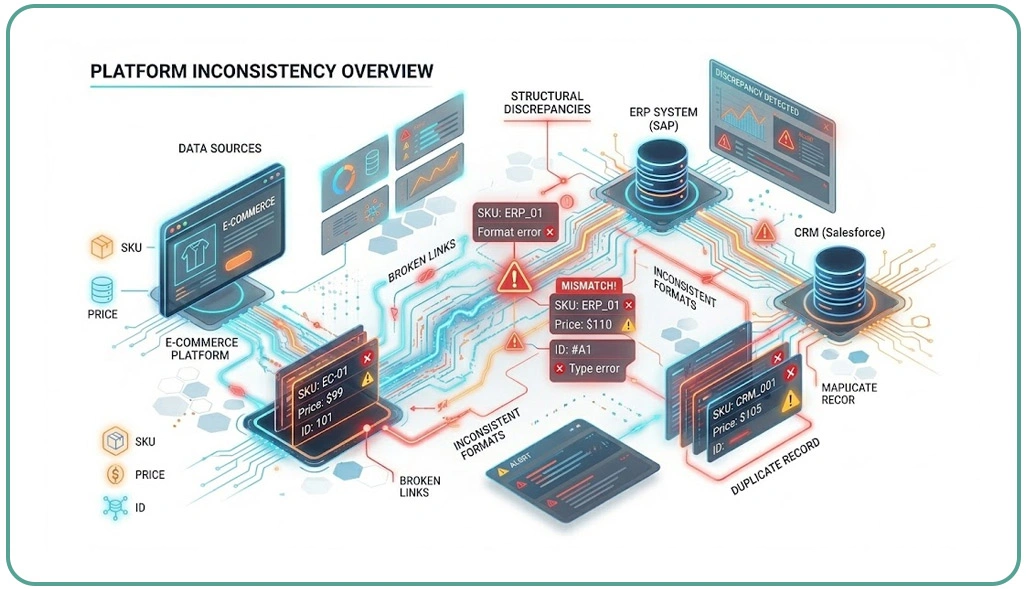
In large-scale data environments, inconsistencies across platforms are one of the primary causes of inaccurate product mapping. Every marketplace structures its catalog differently, leading to variations in product titles, descriptions, and attributes. These inconsistencies significantly contribute to fragmented datasets and unreliable outputs when aligning E-Commerce Datasets across multiple sources.
Another critical issue stems from the lack of uniform identifiers such as SKUs or UPCs. This creates a need for structured matching approaches like Best Techniques for Product Matching in E-Commerce Scraping, which include normalization, tokenization, and similarity scoring. These techniques help in improving the reliability of matching processes across diverse datasets.
Duplicate listings further complicate the situation, as the same product may appear multiple times with slight variations in naming or formatting. Implementing Automating Duplicate Product Detection in Scraped Data becomes essential to reduce redundancy and improve dataset clarity.
Key Causes and Business Impact:
| Issue Type | Root Cause | Business Impact |
|---|---|---|
| Duplicate Entries | Multiple seller listings | Inflated product counts |
| Missing Identifiers | Lack of standardized codes | Incorrect mapping |
| Naming Differences | Platform-specific formatting | Reduced match accuracy |
| Attribute Gaps | Incomplete product details | Poor analytics quality |
Addressing these structural challenges requires a combination of rule-based systems and scalable data engineering strategies to maintain accuracy and consistency across growing datasets.
Analyzing Contextual Variations and Unstructured Data Influence in Matching

Contextual complexity plays a major role in reducing the accuracy of entity resolution processes. Product descriptions, customer reviews, and other unstructured data elements introduce ambiguity that traditional systems struggle to interpret. These issues are commonly categorized under Challenges in Entity Resolution for Web Scraped Data, where understanding context becomes as important as matching structured attributes.
For instance, products with similar names may differ significantly in specifications such as size, material, or version. Without contextual understanding, systems often group these as identical entities, leading to incorrect insights. To address this, advanced approaches like Scrape AI and Machine Learning for E-Commerce Entity Resolution are increasingly being adopted.
Incorporating Sentiment Analysis further enhances contextual understanding by extracting insights from user reviews. This helps differentiate between product variations based on user feedback and usage patterns, providing an additional layer of validation in the matching process.
Contextual Challenges and Solutions:
| Data Element | Challenge Introduced | Solution Approach |
|---|---|---|
| Descriptions | Ambiguous product features | NLP-based parsing |
| Customer Reviews | Unstructured feedback | Sentiment clustering |
| Visual Content | Image inconsistencies | Computer vision models |
| Metadata | Inconsistent attributes | Data normalization |
By integrating contextual intelligence into data pipelines, organizations can significantly improve the quality of entity resolution and ensure more accurate and actionable outputs.
Managing Data Scale and Integration Complexity in Aggregated Pipelines

As organizations expand their data collection efforts, scaling introduces additional complexities in maintaining consistency across aggregated sources. Large-scale pipelines often ingest data from multiple platforms simultaneously, resulting in overlapping and inconsistent records. These challenges increase the difficulty of maintaining accurate entity mapping, especially when dealing with real-time updates and dynamic datasets.
Frequent updates across platforms create synchronization issues, where product information may vary depending on the source. To effectively manage these challenges, businesses rely on advanced solutions like Scrape Advanced Entity Matching Algorithms for E-Commerce Datasets, which are designed to handle high-volume and multi-source data efficiently.
Another critical aspect is incorporating Review Scraping Services, which provide additional insights into product variations and help refine matching accuracy. These services extract valuable contextual information that supports better alignment across datasets.
Scalability Challenges and Solutions:
| Challenge | Description | Recommended Solution |
|---|---|---|
| High Data Volume | Large-scale ingestion | Distributed processing systems |
| Real-Time Updates | Frequent data changes | Incremental syncing |
| Multi-Source Inputs | Diverse data formats | Unified data models |
| Regional Differences | Localization variations | Context-aware matching |
Successfully managing scale requires a balanced approach that combines automation, intelligent algorithms, and efficient data processing frameworks to ensure consistent and accurate outputs across complex pipelines.
How Web Data Crawler Can Help You?
In large-scale retail intelligence systems, aligning fragmented product data across platforms demands a structured and technology-driven approach. Addressing E-Commerce Data Entity Resolution Issues in Web Scraping requires not only advanced tools but also a strategic framework that ensures data consistency at every stage of the pipeline.
Key capabilities include:
- Standardizing product attributes across platforms
- Identifying and merging duplicate listings
- Enhancing data accuracy through validation layers
- Integrating scalable data pipelines
- Improving consistency in product categorization
- Supporting real-time data synchronization
With a focus on innovation and efficiency, we also incorporate Scrape AI and Machine Learning for E-Commerce Entity Resolution to deliver precise and scalable data matching solutions tailored to evolving business needs.
Conclusion
As digital commerce ecosystems continue to expand, resolving inconsistencies across datasets becomes increasingly critical for accurate decision-making. Persistent mismatches, duplication, and structural inconsistencies highlight the importance of addressing E-Commerce Data Entity Resolution Issues in Web Scraping through advanced and scalable strategies.
Implementing structured frameworks alongside intelligent systems such as Best Techniques for Product Matching in E-Commerce Scraping ensures better alignment across platforms and improved data reliability. Connect with Web Data Crawler today to build accurate, scalable, and future-ready data pipelines tailored to your business goals.