How Does the Distributed Web Scraping Architecture and Implementation Guide Simplify Large-Scale Crawls?
May 08

Introduction
Enterprise data teams increasingly rely on the Distributed Web Scraping Architecture and Implementation Guide to design scalable crawling pipelines that can handle millions of pages efficiently. As digital ecosystems expand, traditional single-node scraping systems struggle with latency, blocking issues, and data inconsistency. This is where modern distributed approaches reshape how enterprises collect and process web data.
Organizations now integrate Web Scraping Services to extract structured insights from multiple sources simultaneously while maintaining performance stability. However, scaling beyond a certain threshold requires architectural transformation rather than just optimization. In high-volume environments such as e-commerce, travel aggregation, and financial analytics, distributed systems ensure that crawling tasks are executed in parallel without overloading target servers.
This approach also improves data freshness and reduces duplication. By breaking tasks into smaller distributed units, enterprises achieve higher throughput and better resilience. Modern implementations also integrate monitoring layers, proxy rotation systems, and adaptive throttling to prevent bans and maintain scraping continuity. As a result, organizations gain more control over large-scale data pipelines while minimizing infrastructure costs and downtime.
Managing High-Scale Extraction Through Coordinated System Design
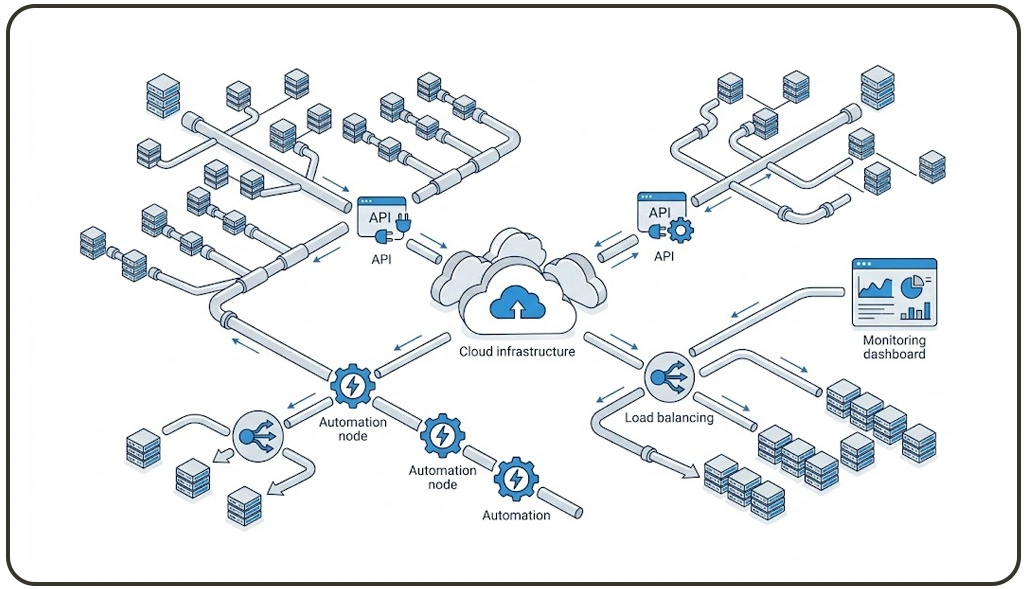
Modern data ecosystems require resilient and scalable frameworks to handle continuous information flow across diverse sources. Real-world applications often combine data extraction with analytical enrichment. For instance, Sentiment Analysis helps convert unstructured text into meaningful insights, particularly in customer feedback and social listening workflows.
The architecture enables segmentation of crawling tasks into smaller units processed across multiple nodes, improving throughput and minimizing latency. Each node operates independently while contributing to a unified data pipeline, ensuring consistency and reliability even under heavy load conditions. This structure is especially useful for organizations processing millions of pages daily.
A structured comparison of system efficiency is shown below:
| System Type | Throughput Level | Fault Recovery | Resource Efficiency |
|---|---|---|---|
| Monolithic Crawling | Low | Weak | Inefficient |
| Distributed Crawling | High | Strong | Optimized |
System design principles also emphasize workload balancing, dynamic task allocation, and retry mechanisms to ensure uninterrupted execution. These features prevent bottlenecks and improve data freshness across pipelines. Additionally, organizations implement Best Practices for Scalable Distributed Scraping Systems to maintain efficiency and avoid system overload.
These include intelligent request throttling, proxy optimization, and adaptive crawling logic. By integrating modular architecture with intelligent orchestration, enterprises achieve higher reliability and scalability. This approach ensures that even complex scraping environments remain stable, efficient, and capable of handling evolving data demands.
Optimizing Parallel Processing and Real-Time Data Collection Pipelines
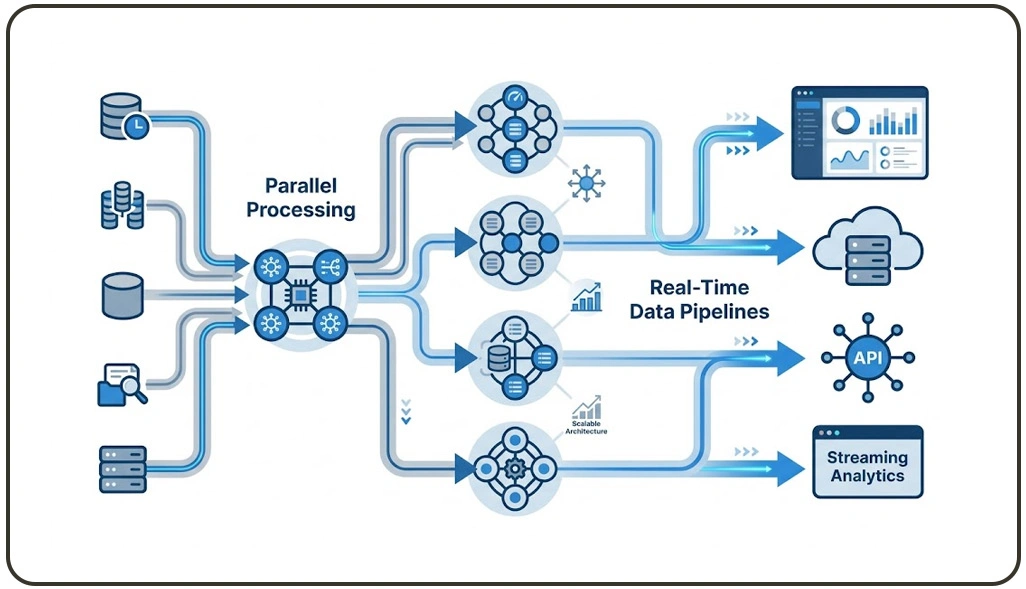
Efficient data extraction at scale depends heavily on optimized parallel processing models and intelligent workload distribution. Distributed systems divide crawling tasks across multiple worker units, enabling simultaneous execution and significantly reducing processing time. This approach ensures that large datasets are processed continuously without performance degradation.
In real-time environments, organizations often deploy Live Crawler Services to capture dynamic updates from e-commerce platforms, financial dashboards, and travel systems. These services integrate seamlessly into distributed frameworks, ensuring uninterrupted data streaming and high-frequency updates.
Performance evaluation across different architectures highlights key differences:
| Metric | Sequential Crawling | Distributed Execution |
|---|---|---|
| Processing Speed | Moderate | High |
| Scalability | Limited | Extensive |
| System Stability | Low | High |
Task scheduling plays a critical role in ensuring balanced execution across nodes. Intelligent schedulers prioritize high-value targets while minimizing redundant requests. This improves efficiency and ensures optimal resource utilization. Horizontal scalability is another major advantage, allowing new nodes to be added dynamically without restructuring the system.
Organizations also adopt Cloud-Based Architecture for Distributed Scraping Systems to achieve elasticity and global accessibility. By combining real-time ingestion capabilities with distributed execution models, enterprises achieve consistent performance, reduced latency, and improved operational efficiency across all data pipelines.
Strengthening Secure Data Pipelines with Intelligent API Integration Systems
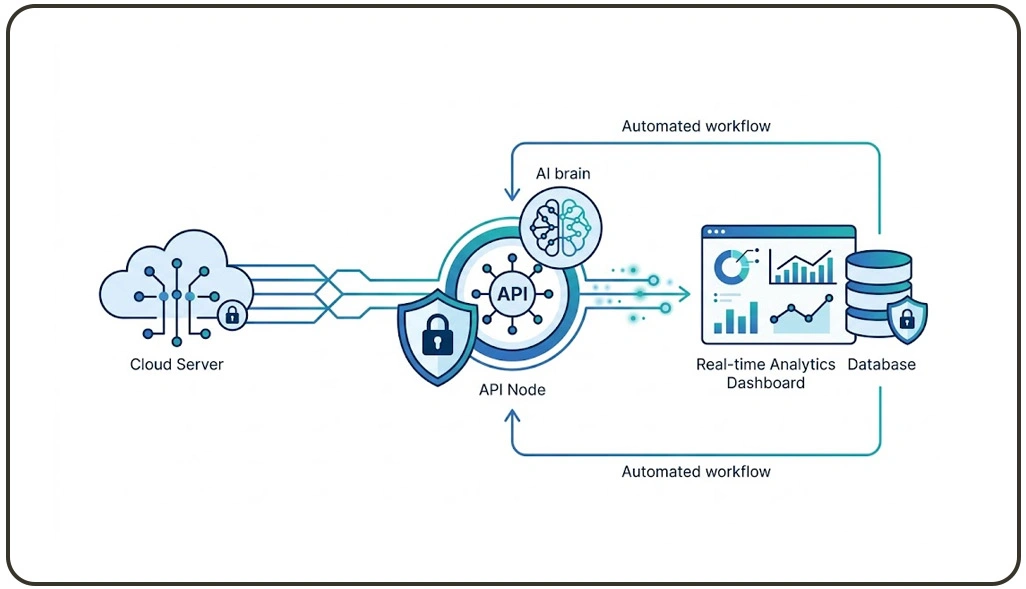
Security and reliability are essential components of modern data extraction frameworks, especially when dealing with high-volume and sensitive data sources. Distributed architectures address these challenges by implementing encrypted communication channels, adaptive routing mechanisms, and centralized monitoring systems.
One of the most important advancements in this domain is the integration of structured APIs that simplify data access and reduce dependency on manual scraping logic. These systems ensure consistent and controlled data flow across multiple environments.
Security comparison overview:
| Security Feature | Basic Systems | Distributed Secure Systems |
|---|---|---|
| Data Encryption | Limited | Advanced |
| Access Control | Basic | Role-Based |
| Monitoring | Minimal | Comprehensive |
To ensure scalability and efficiency, enterprises integrate Scraping API solutions that provide standardized endpoints for structured data retrieval. This reduces system complexity and improves maintainability across large-scale operations. Monitoring frameworks track node health, request success rates, and anomaly detection in real time.
In addition, cloud-native deployment models enhance flexibility and reliability. These systems automatically scale resources based on demand, ensuring consistent performance even during peak traffic periods. The integration of distributed execution with secure API-driven data pipelines results in highly resilient architectures capable of handling complex extraction workflows efficiently.
How Web Data Crawler Can Help You?
The Distributed Web Scraping Architecture and Implementation Guide enables enterprises to build scalable, high-performance data extraction systems tailored for complex environments. It simplifies orchestration of distributed nodes, improves reliability, and ensures continuous data flow across multiple sources.
Our approach includes:
- Design modular crawling systems for enterprise-scale workloads
- Implement efficient task distribution across multiple nodes
- Optimize request handling for high-volume data extraction
- Ensure system resilience with automated failure recovery
- Improve data accuracy through structured validation workflows
- Enable seamless integration with analytics and storage systems
By adopting Large-Scale Web Scraping Infrastructure, organizations can significantly enhance their ability to process massive datasets with speed and accuracy while reducing operational complexity.
Conclusion
The Distributed Web Scraping Architecture and Implementation Guide plays a critical role in modern data engineering by enabling scalable, efficient, and resilient scraping systems. It empowers organizations to manage complex data pipelines while maintaining performance and reliability across distributed environments.
By combining intelligent orchestration and Best Practices for Scalable Distributed Scraping Systems, enterprises can achieve optimized resource utilization and improved data accuracy even under heavy workloads. Partner with Web Data Crawler today to implement enterprise-grade distributed scraping solutions and transform your data strategy into a high-performance intelligence system.