What Benefits Does Designing Large-Scale Web Scraping Systems Step by Step Bring to Modern Enterprises?
May 07

Introduction
Modern enterprises operate in environments where digital information changes every second across e-commerce stores, travel portals, social platforms, financial marketplaces, and business directories. Organizations that fail to collect and process this data efficiently often struggle with delayed decisions, pricing gaps, inaccurate forecasting, and weak customer engagement strategies.
Today, companies increasingly depend on Web Scraping Services to simplify data collection processes while reducing manual operational costs. As enterprise data requirements continue expanding, businesses require infrastructures capable of handling millions of requests, managing proxy rotation, monitoring crawler performance, and storing large datasets without interruptions.
This is where Designing Large-Scale Web Scraping Systems Step by Step becomes critical for sustainable enterprise growth and operational continuity. A structured scraping architecture enables organizations to scale operations across multiple regions while maintaining high-speed extraction accuracy. These advantages continue driving enterprise investments toward scalable scraping infrastructure models designed for long-term performance and operational reliability.
Strengthening Enterprise Intelligence Through Structured Data Automation
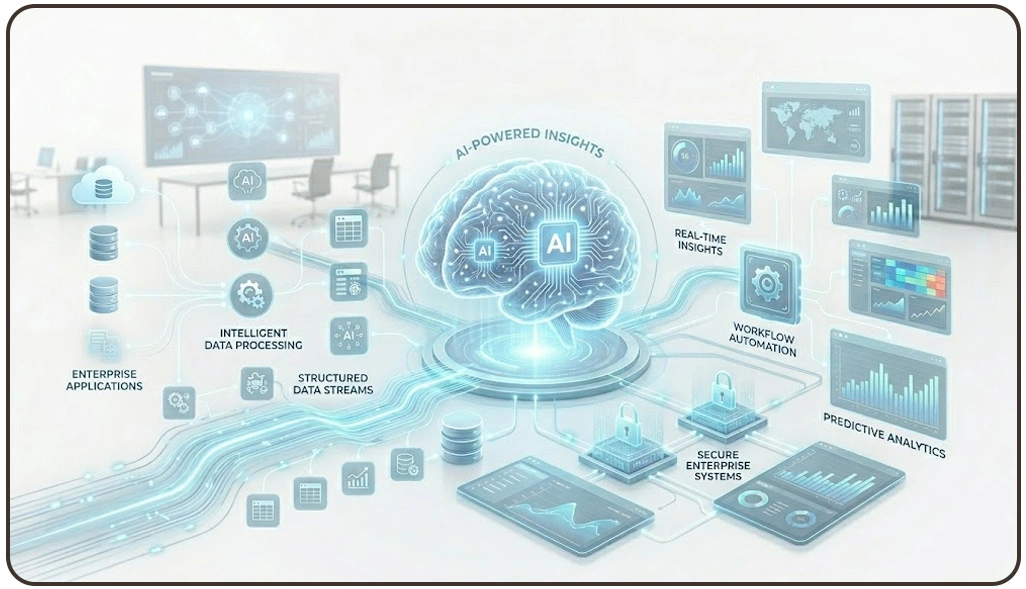
Modern enterprises rely heavily on automated information systems to maintain competitive positioning across rapidly changing digital markets. Businesses processing millions of records daily require scalable infrastructures capable of managing extraction continuity, validation workflows, and organized reporting pipelines. Scalable extraction ecosystems solve these issues by creating automated frameworks that improve operational efficiency and maintain reliable information flow across departments.
Large organizations increasingly invest in distributed architectures to simplify data handling and improve analytical visibility. Additionally, advanced customer insight systems supported by Sentiment Analysis improve brand monitoring by transforming reviews, feedback, and public discussions into measurable business intelligence.
Businesses implementing Enterprise Architecture for Web Scraping and Data Pipelines often improve synchronization between extraction systems, analytics platforms, and storage environments. This structured framework supports better workload distribution while minimizing extraction failures across high-volume digital ecosystems.
| Enterprise Challenge | Automated Infrastructure Solution | Business Impact |
|---|---|---|
| Delayed reporting workflows | Scheduled extraction automation | Faster decision-making |
| Data inconsistency across sources | Centralized validation systems | Improved reporting accuracy |
| Large-scale monitoring difficulties | Distributed crawler management | Better operational stability |
| Unstructured customer feedback | AI-powered processing systems | Improved customer intelligence |
| Regional content variations | Geo-targeted extraction models | Better market visibility |
Modern enterprises continue prioritizing scalable automation infrastructures because organized extraction ecosystems improve long-term operational continuity, reduce downtime risks, and support accurate strategic planning across increasingly competitive industries.
Improving Multi-Regional Performance Across Distributed Systems
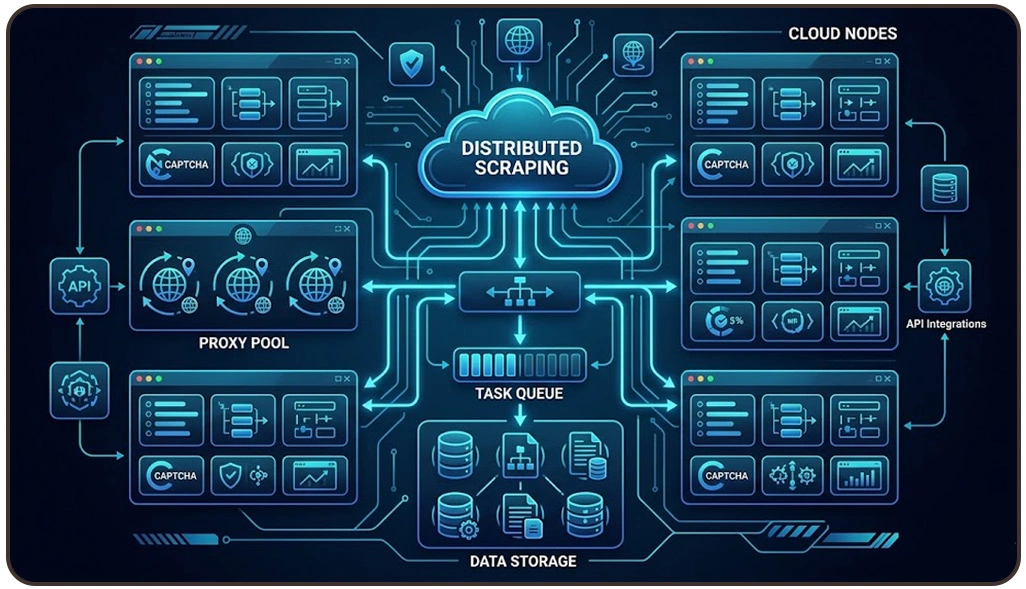
Global enterprises operate within digital ecosystems where information changes continuously across marketplaces, review platforms, travel websites, and competitive business environments. Managing extraction activities across these regions requires scalable infrastructures capable of balancing workloads, handling regional restrictions, and processing high-volume datasets without interruptions.
Enterprises increasingly prefer to Build Distributed Scraping Systems Using Cloud Infrastructure because cloud deployment environments provide dynamic scalability, automated resource balancing, and centralized operational visibility. These systems allow businesses to manage extraction workflows across multiple regions while maintaining high-speed data collection accuracy and uninterrupted operational continuity.
Additionally, modern Live Crawler Services help enterprises monitor pricing fluctuations, inventory changes, customer activities, and product availability in real time. Businesses using these services often improve response times while reducing delays in analytical reporting and competitive intelligence tracking.
| Operational Requirement | Distributed Technology Solution | Enterprise Advantage |
|---|---|---|
| Large-scale extraction demand | Multi-server deployment systems | Improved scalability |
| Frequent blocking restrictions | Intelligent proxy balancing | Better extraction continuity |
| Regional monitoring operations | Geo-distributed infrastructures | Enhanced localized visibility |
| High traffic fluctuations | Elastic resource scaling | Reduced downtime risk |
| Real-time reporting needs | Automated task orchestration | Faster operational response |
Businesses also continue investing in Cloud-Based Architecture for Large-Scale Data Extraction because centralized cloud environments simplify monitoring, infrastructure maintenance, and enterprise-level scalability management.
Enhancing Automation Reliability Through Advanced Extraction Technologies
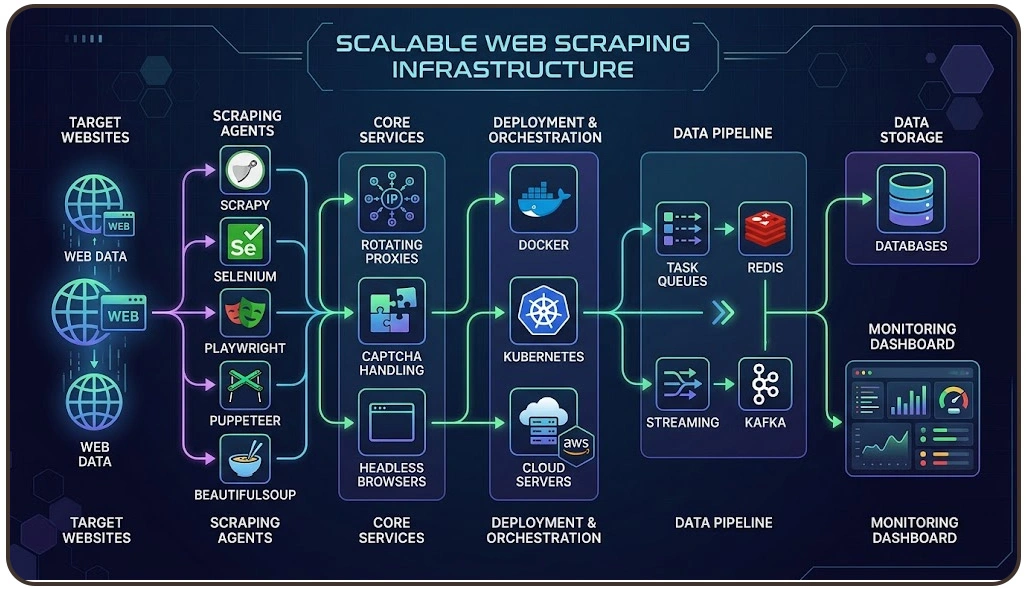
Modern digital enterprises require intelligent automation systems capable of managing highly dynamic websites, anti-bot mechanisms, JavaScript rendering, CAPTCHA interruptions, and large-scale request scheduling. Conventional extraction systems often become inefficient when processing enterprise-level workloads because they cannot maintain operational stability under complex digital environments.
Enterprises increasingly depend on Tools and Frameworks for Scalable Web Scraping Infrastructure because advanced frameworks simplify workload balancing, distributed scheduling, monitoring integration, and large-volume processing operations. These technologies improve scalability while supporting flexible integrations with enterprise analytics platforms and reporting environments.
Businesses also utilize Scraping API solutions to standardize extraction outputs and simplify structured data integration across internal applications. APIs help enterprises improve operational consistency while minimizing disruptions caused by changing website structures or regional content variations.
| Automation Objective | Advanced Technology Applied | Operational Benefit |
|---|---|---|
| Dynamic content rendering | Headless browser automation | Improved extraction accuracy |
| Large-scale request handling | Queue management systems | Faster processing performance |
| Anti-bot restriction management | Smart proxy orchestration | Better operational continuity |
| Cross-platform integrations | API-driven automation systems | Simplified data workflows |
| Infrastructure monitoring | Real-time analytics dashboards | Improved performance visibility |
Large enterprises continue modernizing automation ecosystems because scalable extraction technologies improve long-term operational efficiency, support data-driven decision-making, and strengthen competitive responsiveness across continuously evolving digital industries.
How Web Data Crawler Can Help You?
Modern enterprises require scalable extraction ecosystems capable of handling high-volume digital environments without compromising reliability or performance. Businesses implementing Designing Large-Scale Web Scraping Systems Step by Step often improve operational visibility, accelerate reporting workflows, and strengthen data-driven decision-making processes across competitive industries.
Key Service Advantages:
- Automated multi-platform extraction management
- Distributed proxy rotation for uninterrupted operations
- Real-time monitoring and reporting integration
- High-volume data collection optimization
- Secure cloud deployment and storage workflows
- Flexible scalability for enterprise expansion needs
Our infrastructure expertise also supports businesses seeking advanced Cloud-Based Architecture for Large-Scale Data Extraction to improve centralized monitoring, resource allocation, and enterprise automation performance.
Conclusion
Modern enterprises continue prioritizing scalable automation because digital ecosystems demand faster access to structured information and reliable operational intelligence. Businesses adopting Designing Large-Scale Web Scraping Systems Step by Step improve reporting accuracy, automation stability, and strategic responsiveness across highly competitive industries.
Organizations also benefit significantly from implementing Enterprise Architecture for Web Scraping and Data Pipelines to maintain synchronized workflows between extraction systems, analytics platforms, and reporting environments. Contact Web Data Crawler today to build enterprise-ready scraping solutions tailored for modern digital operations.