How Can Cloud-Based Web Scraping Pipelines Using AWS and GCP Boost Multi-Source Data Collection Speed?
May 11

Introduction
Modern enterprises increasingly depend on automated data collection to monitor competitors, evaluate market movements, and analyze customer behavior across multiple digital channels. This demand has accelerated the adoption of Cloud-Based Web Scraping Pipelines Using AWS and GCP for scalable infrastructure management, faster deployment cycles, and uninterrupted data accessibility.
Organizations integrating automated extraction frameworks into cloud environments often experience better response management, elastic storage allocation, and enhanced parallel processing. Advanced orchestration services available on AWS and Google Cloud enable businesses to deploy distributed crawlers, queue-based processing systems, and real-time analytics pipelines with greater operational stability.
By implementing a reliable Scraping API, enterprises can coordinate data collection from multiple sources simultaneously while maintaining structured workflows and centralized monitoring. These cloud-enabled ecosystems support rapid scaling, improve compliance management, and deliver continuous operational performance for organizations requiring accurate and real-time business intelligence.
Accelerating Large-Scale Operations Through Distributed Processing Frameworks
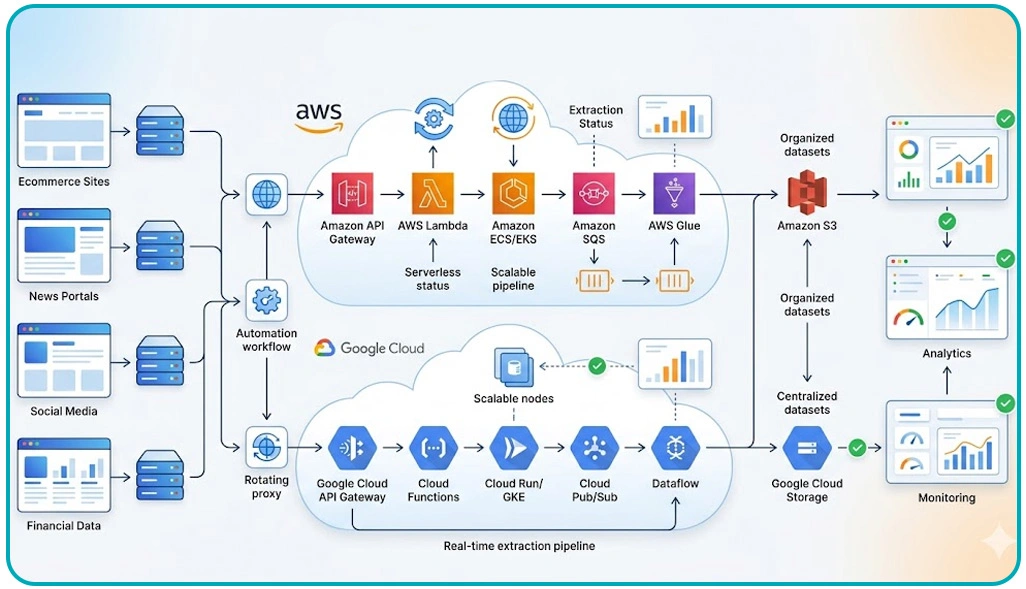
Organizations handling enterprise-level extraction projects often experience delays when traditional infrastructures fail to process simultaneous requests efficiently. Businesses adopting modern cloud orchestration systems overcome these limitations by distributing workloads across scalable environments capable of handling continuous processing cycles without interruption.
The implementation of Web Scraping Architecture on AWS and Google Cloud enables enterprises to organize extraction operations through distributed queues, containerized workers, and centralized orchestration layers. Research shows that organizations using distributed frameworks improve request processing efficiency by nearly 50% compared to conventional server-based extraction systems.
Cloud-native automation also minimizes downtime by enabling failover support and dynamic resource allocation. Intelligent load balancing mechanisms distribute crawler traffic evenly, reducing congestion during peak extraction periods. Advanced monitoring tools further provide real-time visibility into bandwidth utilization, extraction accuracy, and request completion rates across large-scale environments.
| Operational Area | Cloud-Based Improvement |
|---|---|
| Request Handling Speed | 50% Faster |
| Concurrent Extraction Capacity | Highly Scalable |
| Infrastructure Stability | Improved Reliability |
| Workflow Monitoring | Real-Time Visibility |
| Multi-Region Synchronization | Better Performance |
Another operational advantage involves improved synchronization between storage repositories and analytics systems. The integration of a Web Scraping API additionally simplifies communication between distributed extraction layers and downstream applications, supporting secure workflow management across multiple operational environments.
Managing Expanding Information Streams Across Multiple Platforms
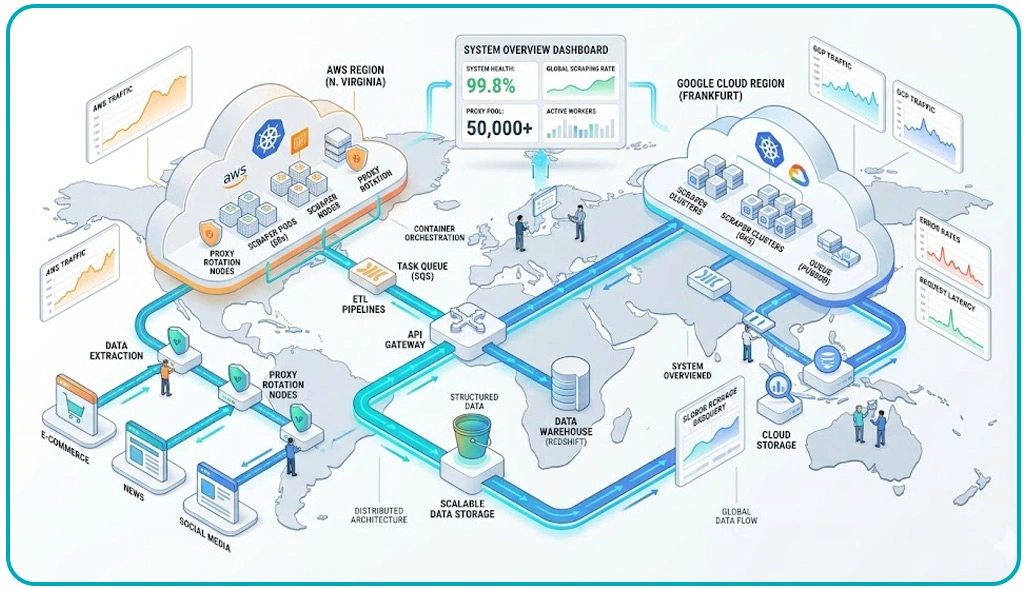
Enterprises collecting information from marketplaces, review portals, travel websites, and social channels often encounter difficulties managing rapidly growing extraction volumes. Traditional infrastructures frequently struggle to process continuous workloads efficiently, especially when handling multiple content formats simultaneously.
Organizations implementing Deploying Distributed Scraping Systems in Cloud Environments can improve workflow continuity through scalable orchestration layers, distributed worker nodes, and intelligent task scheduling systems. Studies indicate that businesses using distributed cloud deployments reduce operational bottlenecks by approximately 55% while maintaining higher extraction accuracy across diverse digital platforms.
Cloud monitoring solutions additionally provide operational transparency through performance tracking dashboards and automated alert systems. As enterprises increasingly depend on real-time intelligence, scalable cloud deployments continue supporting consistent processing performance and uninterrupted information availability for long-term analytics initiatives.
| Performance Challenge | Cloud-Based Resolution |
|---|---|
| Traffic Surges | Auto-Scaling Support |
| Dataset Synchronization Delays | Distributed Queues |
| Large Data Storage | Scalable Repositories |
| Workflow Interruptions | Redundant Deployment |
| Processing Inefficiencies | Automated Orchestration |
Containerized extraction environments also simplify workload management by enabling enterprises to process dynamic web pages, APIs, and structured datasets simultaneously. Businesses handling extensive Web Scraping Datasets further benefit from distributed storage architectures that improve accessibility, backup reliability, and historical dataset management.
Strengthening Continuous Intelligence Through Scalable Infrastructure Strategies
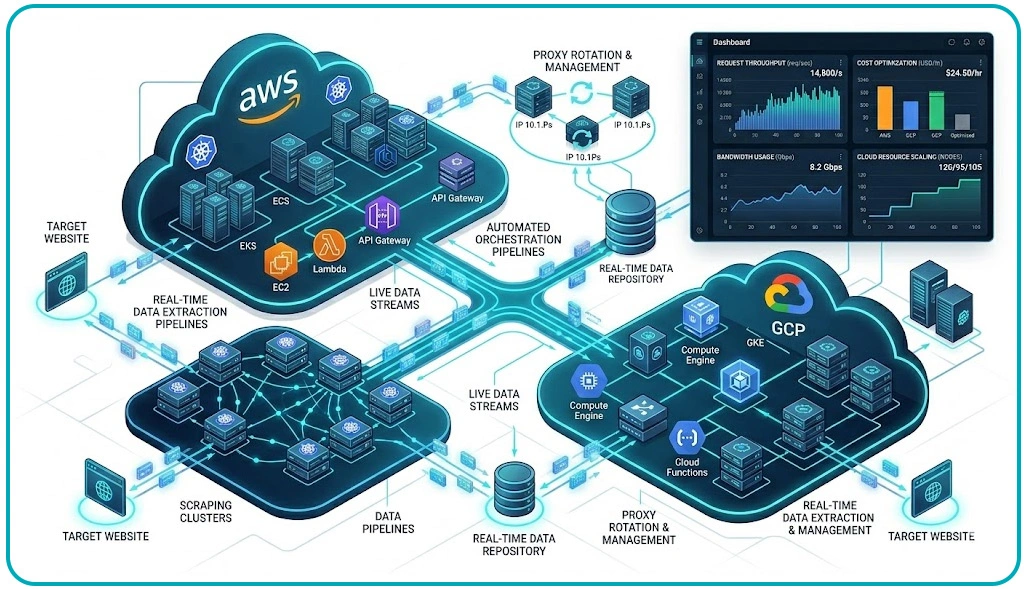
Businesses operating in competitive industries increasingly require immediate access to fresh market information, pricing trends, and customer behavior insights. Traditional extraction environments often lack the flexibility needed to maintain uninterrupted processing across multiple digital channels. Cloud-native automation frameworks help enterprises improve responsiveness while maintaining stable operational performance under continuously changing extraction requirements.
The deployment of Real-Time Data Extraction Pipelines Using AWS and Gcp allows organizations to process updated information through event-driven architectures and distributed synchronization systems. Industry reports indicate that enterprises using real-time orchestration frameworks improve processing efficiency by nearly 58% while reducing manual intervention across extraction workflows.
Businesses utilizing professional Web Scraping Services additionally benefit from automated monitoring systems capable of identifying operational slowdowns before they affect extraction continuity. Intelligent resource scheduling mechanisms dynamically allocate computational capacity during workload spikes, improving infrastructure stability while minimizing unnecessary processing expenses.
| Infrastructure Strategy | Operational Outcome |
|---|---|
| Event-Driven Processing | Faster Synchronization |
| Intelligent Scheduling | Better Stability |
| Distributed Deployment | Reduced Latency |
| Automated Monitoring | Improved Visibility |
| Resource Optimization | Lower Operational Costs |
Operational cost management remains another critical factor for organizations handling large-scale extraction projects. Implementing Optimizing Cloud Infrastructure Costs for Large-Scale Scraping enables businesses to balance computational efficiency with infrastructure spending through automated scaling policies and workload optimization strategies.
How Web Data Crawler Can Help You?
Modern organizations managing enterprise-scale extraction projects require infrastructure that supports flexibility, speed, and operational consistency. Our specialized solutions help enterprises implement Cloud-Based Web Scraping Pipelines Using AWS and GCP with scalable deployment strategies, advanced orchestration systems, and secure multi-source integration capabilities.
We assist organizations with:
- Distributed crawler deployment across multiple cloud regions
- Intelligent queue management for continuous extraction cycles
- Scalable storage integration for large-volume datasets
- Real-time synchronization between extraction and analytics systems
- Automated monitoring for operational stability improvement
- Secure processing workflows for enterprise-grade compliance
Businesses seeking optimized infrastructure management also benefit from our expertise in Optimizing Cloud Infrastructure Costs for Large-Scale Scraping, enabling improved workload balancing, resource allocation efficiency, and long-term operational scalability across cloud-native extraction ecosystems.
Conclusion
Modern enterprises increasingly depend on scalable extraction ecosystems to manage expanding digital intelligence requirements. Organizations implementing Cloud-Based Web Scraping Pipelines Using AWS and GCP improve workflow continuity, accelerate multi-source synchronization, and maintain better operational stability across dynamic online environments.
Businesses also benefit from advanced deployment strategies such as Deploying Distributed Scraping Systems in Cloud Environments, which improve resilience, reduce latency, and enhance large-scale extraction efficiency. Contact Web Data Crawler today to build secure, scalable, and high-performance cloud scraping infrastructures tailored for continuous real-time intelligence operations.