How to Clean and Normalize Scraped Data for Retail Analytics for Smarter Pricing and Insights?
May 05

Introduction
Retail businesses today rely heavily on scraped datasets to understand pricing trends, monitor competitors, and optimize decision-making. However, raw scraped data is rarely usable in its original form. It often contains inconsistencies, duplicate entries, missing values, and formatting issues that can distort insights. Without proper refinement, even the most extensive datasets can lead to flawed conclusions and missed opportunities.
To make data actionable, businesses must Clean and Normalize Scraped Data for Retail Analytics through structured workflows. This process ensures accuracy, consistency, and usability across multiple data sources. From handling incomplete entries to standardizing product information, each step plays a vital role in building reliable analytics systems.
Modern solutions powered by a Web Crawler enable continuous data collection, but cleaning and normalization remain the backbone of transforming raw inputs into strategic intelligence. By implementing systematic approaches, organizations can convert messy datasets into meaningful insights that drive smarter retail decisions and long-term growth.
Ensuring Data Accuracy by Fixing Errors and Removing Redundant Records Efficiently
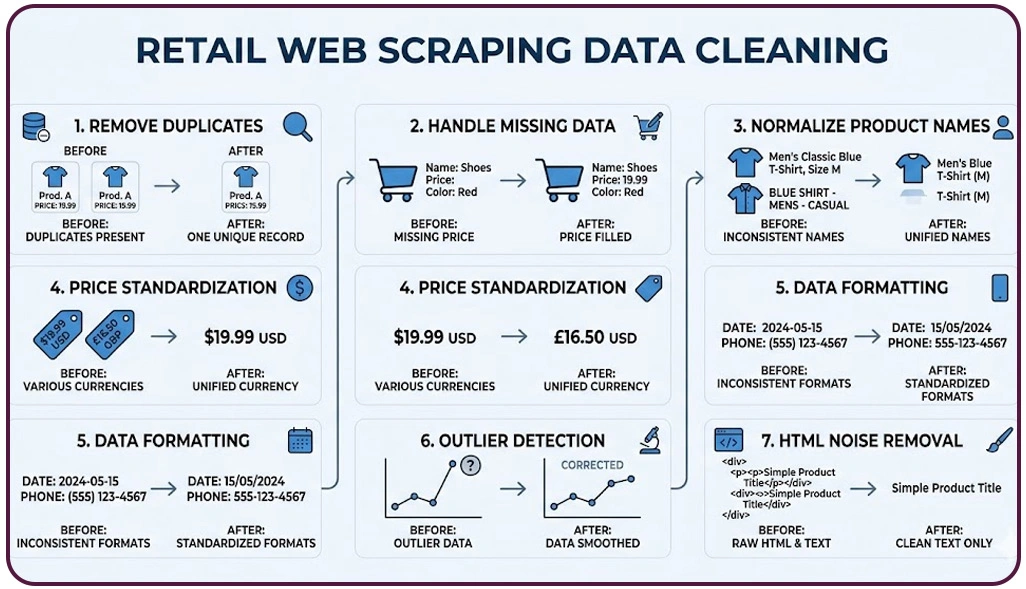
Raw scraped datasets often contain inconsistencies such as duplicate entries, incorrect product labels, and inconsistent formatting. These issues directly impact the reliability of analytics and make it difficult to derive meaningful insights. To overcome such challenges, businesses must implement structured processes that refine and validate collected data before analysis.
Applying Data Cleaning Techniques for Retail Web Scraping helps standardize product attributes, correct naming inconsistencies, and align data structures across different sources. This ensures that datasets remain uniform and comparable. At scale, Enterprise Web Crawling systems gather massive volumes of data, making it even more important to enforce strict quality controls to prevent inaccuracies from spreading across analytics pipelines.
Another crucial step is to Remove Duplicate Data Scraping for Retail, which eliminates repeated entries that can distort pricing comparisons and product counts. Duplicate data often leads to inflated metrics, making it harder to interpret market trends accurately.
| Data Issue | Impact on Analytics | Solution Approach |
|---|---|---|
| Duplicate Records | Inflated product counts | Deduplication algorithms |
| Inconsistent Formats | Difficult comparisons | Standardization rules |
| Incorrect Product Tags | Misclassification | Data validation checks |
| Irregular Price Entries | Skewed pricing insights | Format normalization |
Industry findings suggest that poor-quality data can reduce decision-making efficiency by nearly 30%. By addressing these inconsistencies early, retailers can build a strong analytical foundation and ensure that insights remain accurate, actionable, and aligned with business goals.
Creating Consistent Product and Pricing Structures Across Diverse Retail Data Sources
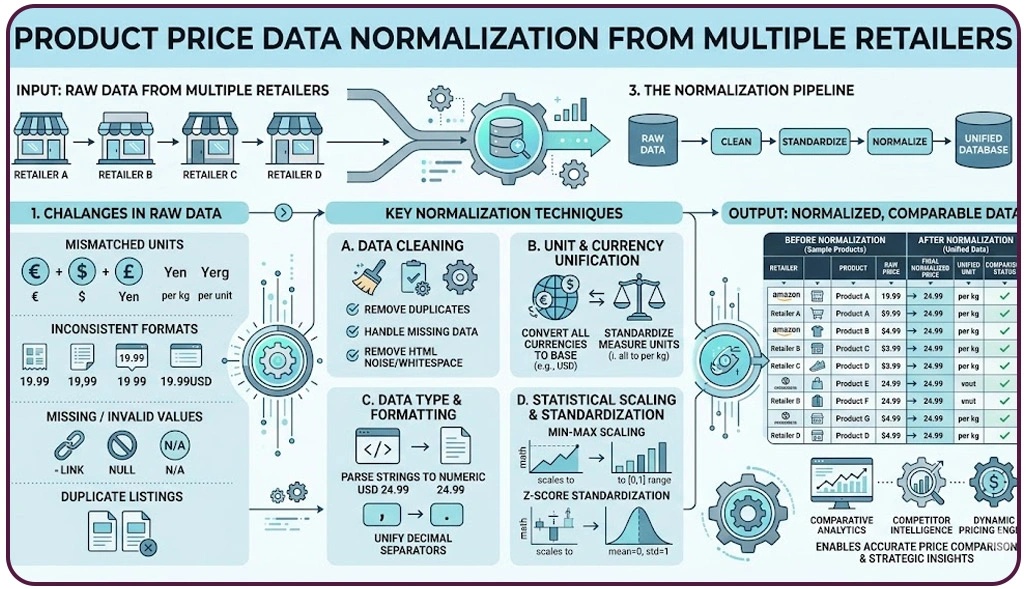
Retail datasets often originate from multiple platforms, each presenting product information in different formats and structures. This variation creates challenges when businesses attempt to compare pricing, analyze trends, or monitor competitors effectively. Establishing consistency across these datasets is essential for accurate and scalable analytics.
One of the most effective approaches involves Structured Data Extraction for Retail Analytics, which organizes product attributes such as names, categories, and specifications into a unified format. This structured approach simplifies data handling and ensures that information can be easily compared across different retail sources.
Another important process is to Normalize Product Price Data From Multiple Retailers, ensuring that all pricing information follows a consistent format regardless of currency, units, or platform-specific differences. This step is crucial for generating accurate comparisons and identifying pricing opportunities.
| Data Element | Variation Across Sources | Standardization Method |
|---|---|---|
| Product Names | Different naming styles | Text normalization |
| Price Formats | Currency & decimal changes | Currency conversion rules |
| Categories | Platform-specific taxonomy | Unified category mapping |
| Units & Measures | Kg vs lbs, ml vs liters | Unit standardization |
These processes play a key role in Market Research, enabling businesses to evaluate competitor pricing strategies, promotional trends, and product positioning with clarity and precision.
Improving Dataset Completeness by Addressing Gaps and Enhancing Data Quality Effectively

Missing or incomplete data is a common challenge in scraped datasets, often leading to gaps in analysis and unreliable business insights. When critical attributes such as prices, product descriptions, or reviews are absent, it becomes difficult to generate accurate forecasts or actionable strategies. Addressing these gaps is essential for maintaining data integrity.
A widely used approach is Handling Missing Values in Scraped Datasets, where incomplete entries are either filled using statistical methods or removed based on their relevance. Research shows that datasets with significant missing values can reduce model performance by over 20%.
Advanced tools like Pandas Data Cleaning Python allow data professionals to efficiently identify missing values, apply transformations, and validate datasets. These tools streamline the cleaning process and improve overall data quality by automating repetitive tasks. By addressing data gaps effectively, businesses can ensure more reliable analytics, better forecasting, and stronger decision-making capabilities.
| Missing Data Type | Impact on Insights | Solution Strategy |
|---|---|---|
| Missing Prices | Incomplete price comparisons | Imputation or removal |
| Missing Attributes | Poor product understanding | Data enrichment |
| Null Reviews | Weak sentiment insights | Data supplementation |
| Incomplete Records | Reduced dataset reliability | Filtering and validation |
Enhanced datasets also support deeper analytical applications such as Sentiment Analysis, where customer feedback and reviews are evaluated to understand consumer perception and improve product strategies.
How Web Data Crawler Can Help You?
Retail businesses aiming for accurate insights must prioritize efficient data processing. When organizations Clean and Normalize Scraped Data for Retail Analytics, they create a strong foundation for reliable pricing strategies and competitive intelligence.
Our approach focuses on delivering consistent, accurate, and actionable data tailored to your retail needs:
- Automated extraction from multiple retail platforms.
- Advanced validation to ensure data accuracy.
- Real-time updates for dynamic pricing insights.
- Custom workflows for specific business requirements.
- Scalable solutions for large datasets.
- Integration-ready outputs for analytics tools.
In addition to these capabilities, we also implement Structured Data Extraction for Retail Analytics to ensure your datasets are organized, standardized, and ready for deeper insights.
Conclusion
Retail success increasingly depends on how effectively businesses manage their data. When organizations Clean and Normalize Scraped Data for Retail Analytics, they eliminate inconsistencies and create a reliable foundation for smarter pricing decisions and strategic growth.
Applying methods like Handling Missing Values in Scraped Datasets ensures completeness and accuracy, allowing businesses to make confident, data-driven decisions. Ready to transform your retail data into actionable insights? Connect with Web Data Crawler today and take your analytics capabilities to the next level.