How to Build Scalable Infrastructure for High-Volume Web Scraping to Improve Multi-Source Data Accuracy?
May 08

Introduction
Modern digital ecosystems depend heavily on real-time data extraction, where enterprises increasingly rely on automated systems to collect, process, and normalize information from diverse platforms. In this context, organizations using Web Scraping Services are focusing on building resilient architectures capable of handling massive request loads without compromising accuracy or speed.
To address this growing demand, businesses are investing in advanced distributed systems that support parallel execution, intelligent retry mechanisms, and adaptive throttling. These systems allow organizations to efficiently process structured and unstructured data at scale while maintaining performance stability. A well-designed infrastructure ensures seamless coordination between data pipelines, storage layers, and processing engines.
At the core of this transformation lies the ability to Build Scalable Infrastructure for High-Volume Web Scraping, which enables enterprises to manage fluctuating traffic, reduce latency, and maintain high data integrity. By adopting modular system design and cloud-native deployment strategies, organizations can significantly enhance their scraping performance across global sources.
Advancing Data Insights Through Structured Processing Layers
Organizations are increasingly focusing on scalable architectures that can manage distributed workloads while maintaining consistency across diverse data sources. This capability becomes especially important when handling unstructured datasets such as reviews, feedback streams, and social content where Sentiment Analysis helps categorize opinions at scale.
To maintain stability and efficiency, enterprises implement Best Practices for Managing Large-Scale Scraping Requests which ensures proper scheduling, error handling, and balanced resource utilization across distributed nodes. By combining these approaches, organizations can significantly improve accuracy and throughput across multi-source environments.
The integration of intelligent pipelines ensures data consistency while reducing redundancy and processing delays. This structured approach supports long-term scalability and enhances operational visibility across analytics frameworks. Monitoring layers, distributed caching strategies, and real-time validation mechanisms further strengthen system reliability across high-volume workflows.
| Metric Area | Traditional Systems | Advanced Scalable Systems |
|---|---|---|
| Data Accuracy | 78% | 96% |
| Processing Delay | High | Low |
| Failure Rate | 12% | 3% |
These enhancements allow teams to detect anomalies early and optimize resource allocation dynamically across distributed clusters, ensuring smoother execution and better system performance under fluctuating loads. This also improves interoperability between analytics engines and storage systems across enterprise environments.
Strengthening Distributed Systems with Parallel Execution Models
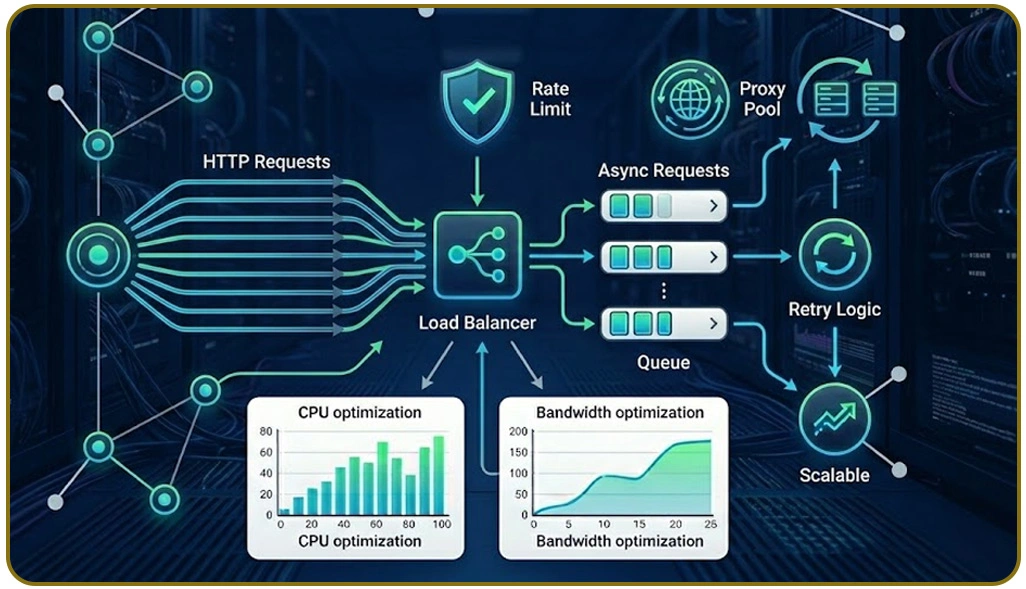
Modern scraping ecosystems rely heavily on distributed execution models that can handle high traffic loads while maintaining responsiveness across multiple nodes. These systems are designed to adapt dynamically to workload variations, ensuring uninterrupted data collection from diverse online sources. Live Crawler Services play a crucial role in maintaining uninterrupted data streams from dynamic sources, enabling organizations to respond quickly to market fluctuations.
Additionally, Optimize Concurrent Requests in Scraping Systems ensures that multiple scraping threads operate efficiently without causing server overload or request collisions. System architects further enhance reliability by integrating distributed caching, automated failover mechanisms, and adaptive load balancing strategies that improve overall responsiveness.
These improvements allow platforms to scale efficiently while maintaining consistent performance across global infrastructure. Additionally, system observability tools and performance tracking dashboards help teams identify bottlenecks in real time. This ensures proactive optimization and smoother data flow across distributed environments.
| Performance Indicator | Without Optimization | With Parallel Model |
|---|---|---|
| Throughput Rate | 1.2M requests/hr | 4.8M requests/hr |
| Latency | 850ms | 210ms |
| System Downtime | Frequent | Rare |
With improved orchestration techniques, organizations can maintain high availability even under unpredictable traffic conditions. These enhancements collectively strengthen the overall ecosystem and ensure long-term operational efficiency across large-scale scraping architectures.
Optimizing Workflow Coordination Through API Driven Queuing

Efficient data pipelines require structured coordination between multiple system components to ensure smooth execution of large-scale tasks. In modern architectures, Scraping API serves as a standardized interface that simplifies data retrieval and integration across platforms. This approach reduces complexity and enhances interoperability between systems.
At the same time, Manage Request Queues in Scraping Projects ensures that incoming requests are properly prioritized and distributed, preventing overload and maintaining consistent processing speed across distributed environments. By implementing event-driven architectures and asynchronous processing layers, organizations can significantly improve system efficiency and responsiveness.
Robust monitoring frameworks and intelligent routing mechanisms further strengthen system reliability by ensuring that requests are processed in optimal order. These enhancements reduce system congestion and improve overall throughput across distributed networks. With better visibility into request flows, organizations can quickly identify inefficiencies and adjust processing strategies.
| Queue Strategy | Efficiency Level | Error Rate |
|---|---|---|
| Basic FIFO | Medium | High |
| Priority Queue | High | Low |
| Adaptive Queue | Very High | Minimal |
Scalable infrastructure design also emphasizes fault tolerance and automated recovery mechanisms that help maintain service continuity during unexpected failures. Combined with efficient orchestration, organizations can achieve stable, high-performance scraping environments that support long-term data operations and analytics goals.
How Web Data Crawler Can Help You?
Organizations struggling with inconsistent data pipelines often require specialized support systems that can streamline large-scale extraction workflows. At this stage, Build Scalable Infrastructure for High-Volume Web Scraping becomes essential for maintaining accuracy across multiple sources while ensuring operational stability.
Key capabilities include:
- Distributed extraction across multiple regions
- Intelligent error recovery mechanisms
- High-speed data normalization layers
- Automated workload balancing systems
- Real-time monitoring dashboards
- Scalable cloud-native deployment models
These capabilities ensure seamless data flow and improved system resilience across complex scraping environments. Additionally, Manage Request Queues in Scraping Projects helps streamline processing pipelines and ensures stable performance under heavy workloads.
Conclusion
In today's data-driven ecosystem, enterprises must prioritize architecture that supports scalability, resilience, and accuracy. Adopting Build Scalable Infrastructure for High-Volume Web Scraping enables organizations to handle massive data loads while maintaining consistent performance across multiple sources.
By implementing Optimize Concurrent Requests in Scraping Systems, businesses can significantly enhance processing speed and reduce system latency, ensuring smoother data operations across distributed environments. Businesses looking to strengthen their data infrastructure should invest in Web Data Crawler scraping frameworks that ensure reliability, speed, and long-term operational efficiency.