What Makes Best Proxy Management Strategies for Large-Scale Scraping Essential for Large-Scale Scraping?
May 08

Introduction
In today's data-driven ecosystem, enterprises depend heavily on structured and unstructured data collection to drive decisions, optimize pricing, and understand market behavior. However, at scale, data extraction becomes complex due to IP blocks, request throttling, and geo-restrictions. This is where advanced proxy orchestration becomes a core foundation of modern scraping systems.
Organizations using Web Scraping Services often face challenges such as inconsistent response rates and blocked sessions when scaling across multiple sources. Efficient proxy systems help distribute traffic intelligently, ensuring smoother data flow and reduced detection risks.
Modern architectures require more than just basic proxy rotation; they demand intelligent routing, failover mechanisms, and adaptive identity handling. Without these, scraping pipelines risks downtime and data inconsistency. As enterprises grow their data footprint, Best Proxy Management Strategies for Large-Scale Scraping become essential not just for performance but also for compliance, scalability, and long-term sustainability in data operations.
Structured Traffic Distribution Across Large Data Networks
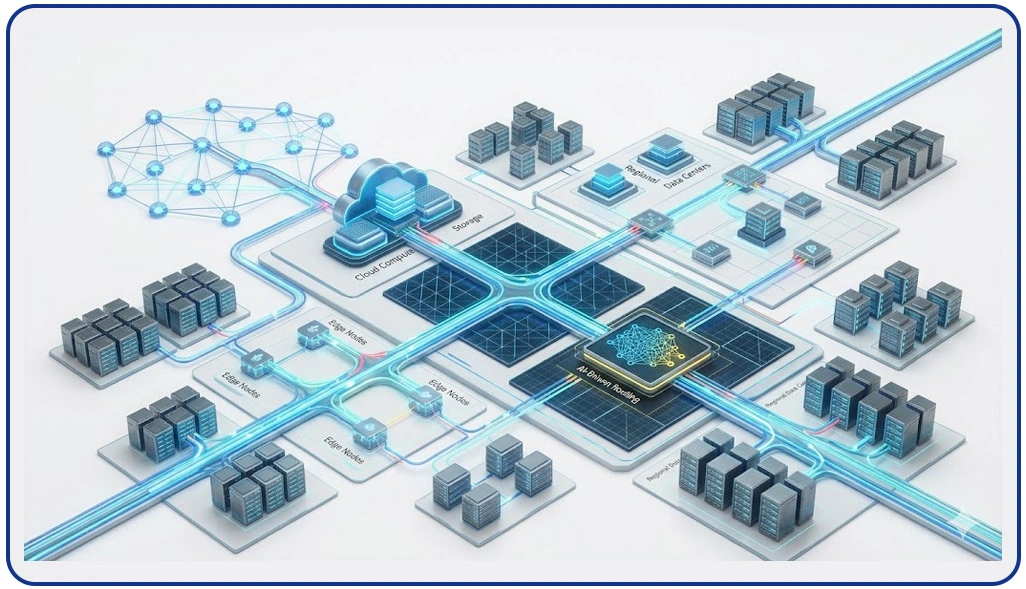
Modern data extraction environments require controlled and intelligent request distribution to ensure uninterrupted access to large datasets. As scraping volumes increase, unmanaged traffic can lead to IP bans, throttling, and inconsistent results. Organizations address these challenges through layered routing systems that distribute requests efficiently across multiple endpoints while maintaining stability and anonymity.
This approach is strengthened when organizations integrate Manage Rotating Proxies in Web Scraping Projects, ensuring dynamic IP switching based on load conditions and target responses. In analytical ecosystems, scraped data is further processed for insights like Sentiment Analysis, improving decision-making accuracy.
Key operational improvements:
- Reduced request failure rates across multiple sources
- Balanced traffic distribution across global endpoints
- Improved session stability under high concurrency
- Lower detection probability from target servers
- Enhanced scalability for enterprise-level data pipelines
Traffic optimization comparison:
| System Type | Failure Rate | Stability | Scalability |
|---|---|---|---|
| Unmanaged Requests | High | Low | Limited |
| Structured Proxy Routing | Low | High | Strong |
A well-architected proxy layer ensures that scraping systems remain resilient even during peak demand cycles. It also improves efficiency in industries like retail analytics, travel pricing, and financial monitoring where continuous data access is essential. Without such systems, extraction workflows often suffer from interruptions, incomplete datasets, and increased operational costs.
Distributed Network Efficiency With Adaptive Routing Layers
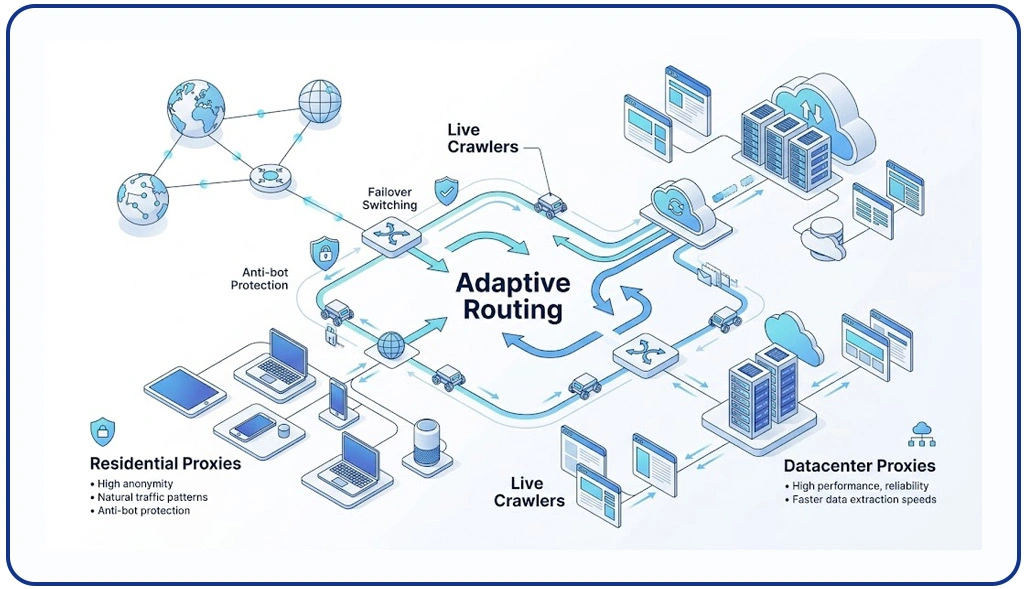
Large-scale scraping infrastructures rely heavily on distributed systems that manage data extraction across multiple geographic regions. As websites deploy stricter anti-bot mechanisms, enterprises must design adaptive routing layers that ensure uninterrupted access while maintaining speed and reliability.
The effectiveness of these systems improves significantly when using Residential vs Datacenter Proxies for Scraping, as each proxy type serves a distinct role in balancing anonymity and performance. In parallel, organizations operating Live Crawler Services benefit from real-time adjustments that help maintain continuity even when target websites change structure or implement new restrictions.
Core advantages of distributed routing:
- Improved geo-location flexibility for global data access
- Faster response handling through distributed nodes
- Reduced server-side detection risks
- Continuous uptime through failover mechanisms
- Enhanced adaptability to changing website structures
Performance comparison of proxy environments:
| Routing Method | Speed | Detection Risk | Cost Efficiency |
|---|---|---|---|
| Centralized System | Medium | High | Medium |
| Distributed Proxy Network | High | Low | High |
These structured systems are essential for maintaining accuracy and reliability in enterprise data pipelines. They also reduce operational strain by automating routing decisions and minimizing manual intervention. Over time, such architectures significantly enhance scraping efficiency while ensuring scalability across global markets.
API-Centric Automation for Scalable Data Extraction Systems

Modern scraping ecosystems are increasingly shifting toward API-driven architectures that centralize control over proxy operations and data flow management. This allows enterprises to automate large-scale extraction processes while maintaining precision, reliability, and speed across diverse digital environments.
A key component in this transformation is Proxy Management for Web Scraping, which enables centralized monitoring and intelligent distribution of proxy resources across multiple scraping nodes. When combined with automation systems like Scraping API, organizations can streamline request handling, reduce latency, and improve overall system responsiveness in real time.
System enhancements enabled by API-driven design:
- Centralized proxy lifecycle management
- Automated failure detection and recovery
- Real-time traffic monitoring dashboards
- Scalable integration with analytics pipelines
- Reduced operational overhead in large deployments
Performance impact comparison:
| Architecture Type | Response Time | Automation Level | Maintenance Effort |
|---|---|---|---|
| Manual Proxy Setup | Slow | Low | High |
| API-Driven System | Fast | High | Low |
Such systems allow businesses to operate highly efficient scraping infrastructures without constant manual oversight. They also ensure that data pipelines remain stable even under fluctuating traffic conditions. As enterprises continue to scale, API-based proxy orchestration becomes a critical foundation for sustainable and intelligent data extraction ecosystems.
How Web Data Crawler Can Help You?
Best Proxy Management Strategies for Large-Scale Scraping play a crucial role in enabling enterprises to collect reliable data at scale without interruptions or performance degradation. We build intelligent systems designed to manage proxy infrastructures efficiently, ensuring smooth extraction workflows across complex digital environments.
Key capabilities include:
- Designing scalable proxy architectures for global data collection
- Implementing intelligent request distribution mechanisms
- Enhancing scraping resilience under high traffic loads
- Optimizing data extraction speed across multiple endpoints
- Supporting automated failover and recovery processes
- Ensuring consistent data quality across large datasets
These solutions are tailored to improve operational efficiency and reduce scraping failures caused by network restrictions or server limitations. By combining intelligent proxy orchestration with Manage Rotating Proxies in Web Scraping Projects, organizations achieve higher success rates in data collection pipelines while maintaining compliance and performance standards.
Conclusion
Effective data extraction at scale requires robust infrastructure and intelligent routing systems that ensure stability under heavy load conditions. Best Proxy Management Strategies for Large-Scale Scraping enable organizations to maintain uninterrupted access to critical data sources while optimizing performance across distributed environments.
As enterprises continue to evolve their data ecosystems, Residential vs Datacenter Proxies for Scraping provides a balanced approach to selecting the right proxy architecture for speed, anonymity, and reliability across diverse scraping needs. Contact Web Data Crawler today and transform your scraping infrastructure into a high-performance intelligence engine.