How Can Best Data Validation Techniques for Scraped Datasets Prevent 90% of Invalid Records?
May 07

Introduction
Modern enterprises rely heavily on automated extraction systems to manage large-scale business intelligence, pricing analysis, customer behavior tracking, and operational monitoring. However, inaccurate or incomplete information collected through scraping pipelines often creates major issues for analytics teams. The increasing demand for scalable Web Scraping Services has encouraged organizations to improve data quality control procedures before integrating collected information into business systems.
According to recent industry estimates, poor-quality datasets can increase processing costs by over 30% and reduce analytical accuracy by nearly 40%. Enterprises are now implementing layered validation models that identify incorrect records before they affect downstream applications. The Best Data Validation Techniques for Scraped Datasets help organizations improve extraction reliability, reduce operational interruptions, and maintain standardized structures for enterprise reporting.
Advanced validation mechanisms also support better automation performance, allowing organizations to process structured information faster without manual review. From ecommerce monitoring to travel intelligence and market research, validation strategies have become essential for ensuring accurate and scalable data operations across industries worldwide.
Establishing Reliable Structures Across Complex Information Pipelines
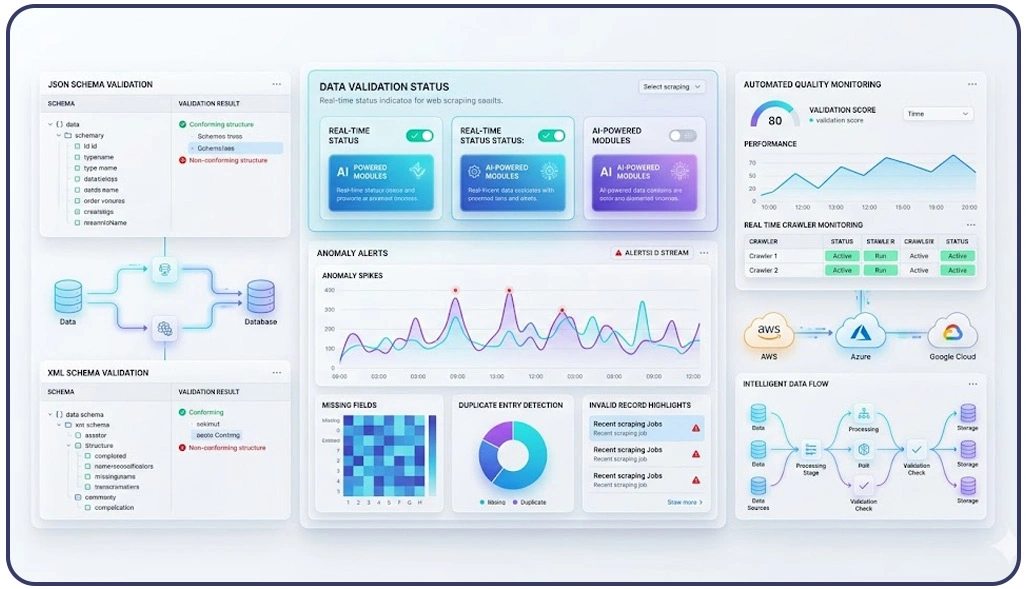
Large-scale extraction environments often collect inconsistent and unstructured information from multiple digital platforms, creating significant operational challenges for analytics teams. Businesses processing millions of records daily require advanced verification mechanisms to ensure information accuracy before integrating datasets into reporting systems.
Organizations now implement automated frameworks capable of comparing incoming records against predefined validation rules. These systems help maintain consistency while improving operational scalability across ecommerce, travel, retail, and research industries. One of the most effective methods involves Schema Validation for Web Scraping Data, where extracted fields are checked against expected formats before storage begins.
Enterprises also deploy machine-learning systems to Detect Anomalies in Scraped Data by identifying irregular patterns, duplicate entries, unusual spikes, and incomplete records during extraction workflows. Automated anomaly detection significantly improves dataset reliability and reduces the manual workload required for quality assurance operations.
Validation Performance Improvements:
| Validation Parameter | Before Automation | After Automation |
|---|---|---|
| Invalid Records | 36% | 4% |
| Duplicate Entries | 21% | 2% |
| Missing Field Errors | 19% | 1% |
| Processing Delays | 42% | 7% |
| Reporting Accuracy | 63% | 97% |
Reliable information pipelines further support advanced business intelligence functions such as customer behavior tracking and Sentiment Analysis, where accurate datasets directly impact analytical precision.
Strengthening Instant Verification Across Dynamic Collection Systems
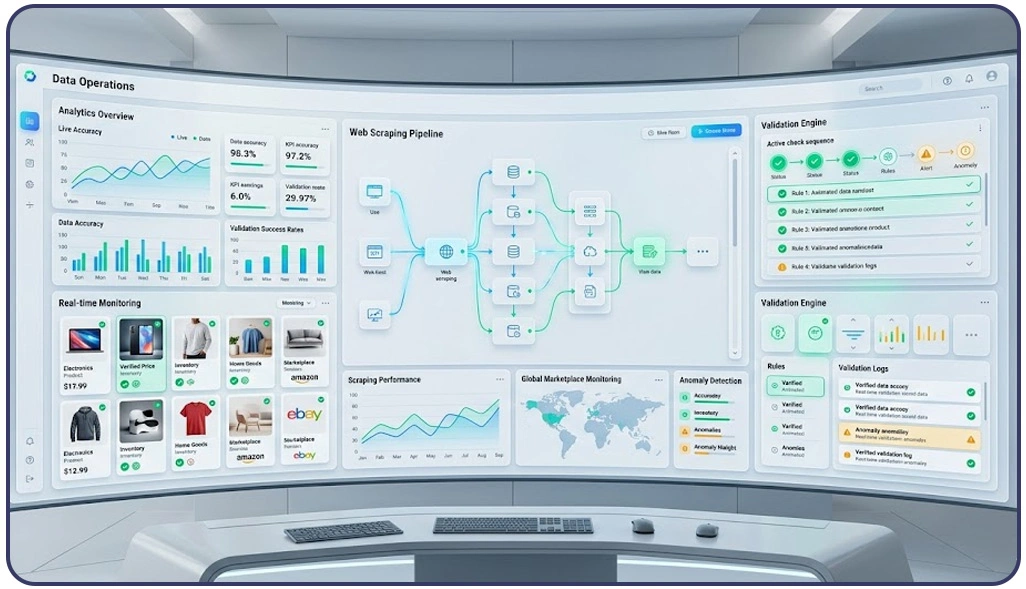
Digital platforms continuously modify product listings, pricing structures, inventory details, and marketplace information, making automated verification systems essential for maintaining reliable enterprise datasets. Businesses operating across ecommerce, finance, travel, and retail environments frequently face challenges caused by outdated, incomplete, or incorrectly formatted records entering analytical pipelines.
Automated systems capable of performing Real-Time Data Validation Techniques for Scraping immediately verify extracted information after collection. These frameworks compare incoming records against predefined business rules, ensuring accurate values before storage begins. Real-time validation minimizes operational interruptions while significantly improving scalability across high-volume extraction infrastructures.
Businesses managing rapidly changing pricing environments especially benefit from instant verification frameworks. Dynamic marketplaces frequently update currency formats, stock availability, and promotional pricing structures, which may create reporting inconsistencies if validation layers fail to identify irregularities immediately.
Real-Time Operational Efficiency Metrics:
| Operational Indicator | Traditional Verification | Automated Verification |
|---|---|---|
| Verification Duration | 14 Minutes | 2 Minutes |
| Dataset Consistency | 67% | 98% |
| Manual Intervention | 48% | 4% |
| Extraction Failure Rate | 23% | 2% |
| Monthly Downtime | 15 Hours | 2 Hours |
Infrastructure providers also integrate performance monitoring mechanisms alongside Live Crawler Services to evaluate extraction stability in real time. These systems identify source-level changes, monitor crawler efficiency, and trigger automated correction workflows whenever inconsistencies appear during collection operations.
Enhancing Business Intelligence Through Accurate Information Management
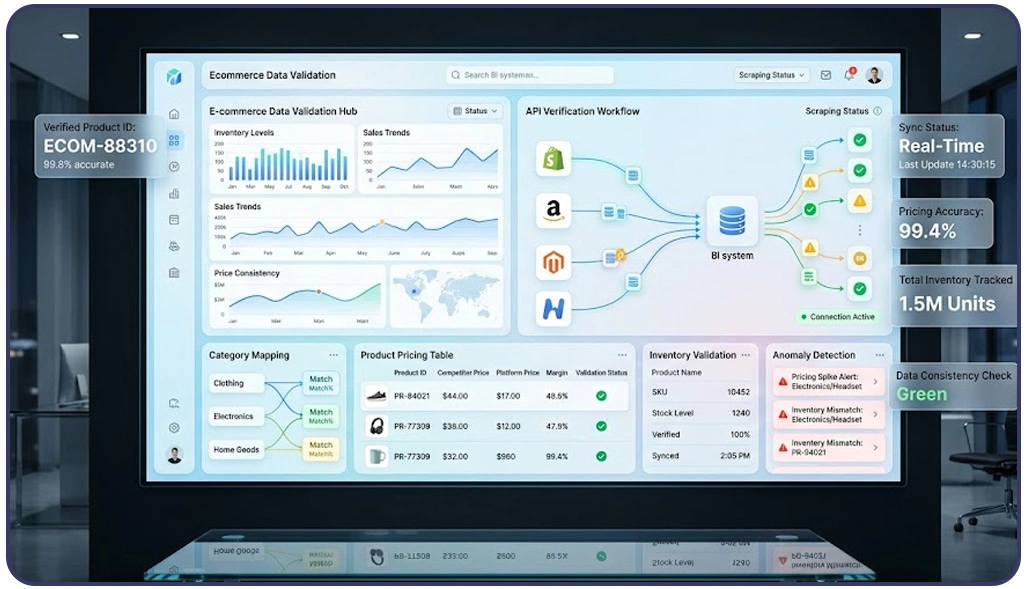
Reliable information management directly influences enterprise forecasting, pricing strategies, customer analytics, and competitive intelligence operations. As organizations continue expanding digital intelligence capabilities globally, advanced verification systems have become essential for maintaining scalable and trustworthy analytical environments.
Many enterprises handling ecommerce intelligence operations now implement structured workflows for Validating Ecommerce Scraped Data Step by Step to ensure extracted pricing, inventory, and product information remains accurate before entering business systems. Automated verification processes check category mappings, product identifiers, availability structures, and pricing consistency to reduce reporting errors and improve long-term operational performance.
Modern validation infrastructures frequently integrate intelligent APIs and automation frameworks capable of maintaining synchronized datasets across multiple platforms. Businesses using advanced Scraping API architectures can automatically compare extracted records against predefined validation rules, identify formatting inconsistencies, and improve extraction stability across large-scale digital ecosystems.
Enterprise Accuracy Improvement Analysis:
| Business Function | Without Structured Validation | With Structured Validation |
|---|---|---|
| Forecasting Accuracy | 57% | 96% |
| Pricing Intelligence Reliability | 62% | 98% |
| Storage Efficiency | 70% | 95% |
| Analytics Processing Speed | 54% | 92% |
| Operational Decision Accuracy | 61% | 97% |
Organizations increasingly recognize that scalable validation systems are essential for maintaining consistent analytics, improving operational forecasting, and supporting sustainable enterprise intelligence management across evolving digital marketplaces.
How Web Data Crawler Can Help You?
Modern enterprises require scalable data management systems capable of handling large volumes of extracted information without compromising reliability. By implementing the Best Data Validation Techniques for Scraped Datasets, organizations can significantly improve operational efficiency while maintaining trustworthy analytics environments for long-term business growth.
Our Core Capabilities:
- Automated duplicate record elimination
- Advanced format consistency monitoring
- Intelligent field verification frameworks
- High-volume extraction quality control
- Real-time operational performance tracking
- Enterprise-scale structured data management
Using Schema Validation for Web Scraping Data, organizations can improve compatibility, maintain consistent reporting structures, and reduce long-term analytical inefficiencies across enterprise operations worldwide.
Conclusion
Reliable data validation frameworks have become essential for enterprises managing large-scale digital intelligence systems. Businesses implementing the Best Data Validation Techniques for Scraped Datasets improve operational accuracy, reduce invalid records, and strengthen long-term analytics performance across dynamic business environments.
Advanced monitoring infrastructures capable of Detect Anomalies in Scraped Data further enhance business reliability by identifying inconsistencies before they impact reporting systems. Contact Web Data Crawler today to build scalable validation pipelines that improve data quality, automation efficiency, and enterprise intelligence performance.